Après avoir abondamment lu et expérimenté avec GPT, je partage ici une réflexion de fond en deux parties sur les modèles dits génératifs qui se résume ainsi: ça change tout (partie 1) et ça ne change rien (partie 2).
Comme le disait Scott Fitzgerald « The test of a first-rate intelligence is the ability to hold two opposing ideas in mind at the same time and still retain the ability to function. One should, for example, be able to see that things are hopeless yet be determined to make them otherwise. »
Le but ici n’est pas de faire thèse, antithèse, synthèse comme on l’a si bien appris à l’école, mais se souligner que l’avènement de cette technologie apporte une grande vague de changement et ne change pas grand-chose à l’affaire, simultanément…
J’essaie, sur base de ma compréhension du fonctionnement de ces modèles et sur l’usage que j’en ai fait, de dessiner les contours de ce que permet cette technologie, réellement, aujourd’hui, tout en pointant les postures de ceux qui d’un côté n’y voient rien de nouveau sous le soleil ou d’un autre côté la fin de l’humanité, ou encore la huitième merveille du monde. En produisant un tel texte, je contribue au “hype” déjà exagéré autour de cette technologie, mon but est pourtant de dégonfler la bulle.
Comprendre la bête
Pour commencer, je propose de déconstruire la bête. Un modèle comme ChatGPT est un tout et pourtant il repose sur des fonctions qu’on peut isoler, au moins logiquement. Je sais qu’avec une approche réductionniste je vais à l’inverse de la logique de ces modèles, toutefois nommer des fonctions permet de mieux comprendre les points de vue différents et comment ils s’agencent.
Fonction 1: Produire du contenu cohérent
On parle de modèle génératif, produire du contenu est donc la fonction première. Il a beaucoup été souligné que les modèles génératifs sont du radotage stochastique, mettant l’accent sur l’aspect probabiliste dénué de toute compréhension. Et c’est ce que c’est: en jouant dans le playground de OpenAI, il est possible d’afficher les probabilités de chaque “token”, montrant à quel point, il s’agit effectivement d’une suite de statistiques.
Tout en soulignant cet aspect stochastique, il est difficile de nier la cohérence du contenu produit. Personnellement, j’assimile la production textuelle d’un ChatGPT à un phénomène émergent, c’est-à-dire qu’une nouvelle propriété émerge d’une somme d’éléments nombreux qui ne présentaient pas cette propriété individuellement. L’émergence est un phénomène très présent dans le monde biologique, l’exemple le plus commun était une fourmilière ou un essaim d’abeilles. Ici, la notion d’émergence renvoie au fait que le produit textuel va au-delà de la simple probabilité d’aligner des syllabes.
Il n’est évidemment pas question ici de parler de compréhension, d’intention et encore moins de conscience. En revanche, on ne peut nier que même la version initiale de ChatGPT était qualitativement supérieure au GPT3 de base rendu public en 2021, et se plaçant dans la zone du fameux test de Turing. L’aspect de cohérence est important à deux titres:
- Cela en fait en contenu compréhensible à peu près à tout coup
- Effet corollaire: ça peut amener de la confusion avec la production d’un humain, voire donner l’impression d’une intention qui n’existe pas.
Ceci dit, pour souligner cet aspect de cohérence, et notamment de progression dans cette capacité de cohérence, le meilleur exemple se trouve dans le domaine visuel avec Midjourney. Depuis la version 3, Midjourney arrivait à produire des images non seulement esthétiques, mais aussi cohérentes… sauf à une mauvaise habitude près: mettre plus que 5 doigts aux mains. Toutefois, l’arrivée de la version 5 a permis de dépasser ce problème. Désormais, les images nous font généralement grâce de mains polydactyles. Au-delà de cet aspect, je trouve frappant la cohérence des images; Midjourney est capable de gérer des reflets, des ombres ou encore des plis de vêtement. C’est pour moi un exemple de phénomène émergent où la somme des informations ingérées permet de reproduire des situations cohérentes et réalistes sans avoir besoin de comprendre les lois physiques ou même les principes généraux du concept d’ombre ou de reflet.

Fonction 2: Interpréter le langage humain
Ça peut sembler une évidence qu’un modèle qui produit du texte est capable d’interpréter, et pourtant ce n’est pas si évidemment quand on y réfléchit: les modèles de langage utilisés ont une capacité productive sur base d’un texte existant; c’est de la ‘complétion’. Les mécanismes de complétion sont assez courants, intégrés par exemple aux claviers des téléphones cellulaires qui proposent le mot le plus probable. Les mécanismes de complétion classique n’ont qu’une compréhension limitée du contexte. Les modèles de langage comme GPT ont deux capacités supplémentaires:
- Ils sont capables d’intégrer un large contexte (i.e du texte antérieur)
- Ils reposent sur des mécanismes de proximité sémantique qui leur permet de savoir que deux termes sont “proches”. Même sans contexte, ces mécanismes permettent de savoir que ‘navire’ et ‘bateau’ sont sémantiquement proches. Avec du contexte, un modèle peut considérer que ‘Sean Connery’ et ‘Roger Moore’ sont des termes proches si le contexte précédent traite de James Bond.
Techniquement, un échange de questions/réponses n’est rien d’autre qu’une complétion pour GPT. Toutefois, d’un point de vue fonctionnel, cela devient une capacité à interpréter une demande et d’y répondre ou de recevoir une instruction et de l’exécuter (par exemple faire un résumé d’un texte).
Fonction 3: Connaitre tout… et inventer au besoin
Ce dernier point est celui qui cause le plus de confusion et c’est aussi pour cela que je jugeais important de distinguer des fonctions. Comme je l’ai lu quelque part, les connaissances d’ensemble d’un GPT sont presque un heureux hasard (ou pas) résultant du mode de création de ces modèles de langage. En lui fournissant des quantités colossales de données, le modèle devient capable d’intégrer une partie de l’information qui lui est soumise. Comme l’expliquait un article (critique), des modèles de ce genre sont peuvent être vu comme une forme de compression d’information. Et OpenAI semble avoir renforcé ce comportement de Monsieur je-sais-tout dans les étapes de renforcement et dans la commande système donnée au modèle.
Le point qui est important ici est que c’est une décision d’OpenAI ou de tout développeur de modèle de ce genre de présenter (ou non) leur modèle comme un agent conversationnel encyclopédique. Cette approche a l’avantage de créer plus de “hype” (on y reviendra). Cette connaissance générale a possiblement une certaine importance pour la fonction 2.: la capacité d’interprétation. En effet, GPT démontre une capacité à faire des liens ou des déductions, nécessaire à comprendre des interactions avec des humains et qui peut difficilement être autre chose que le fruit de cette connaissance générale.
Mais voilà: mettre de l’avant cette connaissance encyclopédique suscite aussi le gros de la confusion dans les discussions entourant GPT, même auprès d’experts. Même si cette capacité à donner l’impression de tout connaitre (en fait un artefact de sa fonction première de produire du contenu qui se tient) peut être domptée, elle est perçue comme la fonction dominante d’un GPT et tout ce qui est dérive. Ça ne veut pas dire que cette tendance affabulatrice doit être ignorée non plus.
Ces éléments m’amènent à une première conclusion à savoir que par la suite, je vais parler de modèle dialogique plutôt que génératif. Le terme génératif met trop l’accent sur la première fonction; l’attribut de dialogique met l’accent sur le phénomène émergent mentionné plus haut, à savoir la capacité d’échanger et utilisant le langage humain.
Mais pourquoi faire ça?
Ma question favorite est toujours: pourquoi? Pourquoi des personnes ont-elles jugé qu’il était utile et important d’investir temps et argent pour faire des modèles génératifs, puis de les perfectionner au point de devenir des modèles dialogiques encyclopédiques? La réponse de OpenAI est vague et tourne généralement autour de l’idée de préparer de “bonnes” intelligences artificielles générales, c’est-à-dire des modèles en tous points équivalents ou supérieurs aux compétences cognitives humaines et qui… ne cherchent pas à nous détruire. Je conclurais le présent billet sur les conséquences de cette idéologie de l’intelligence artificielle générale; à ce stade-ci, je veux surtout souligner que c’est une motivation parmi d’autres.
L’objectif historique du traitement automatique du langage naturel (natural language processing) n’est pas aussi démiurgique: il vise à permettre une interaction plus naturelle entre l’homme et la machine. Éviter de passer par un symbolisme normatif contraignant (du code, des fenêtres, des formulaires… un écran) pour interagir avec des outils informatiques.
Dans cet article, je vais (essayer de) me concentrer sur les capacités réelles, présentes et démontrées, d’un modèle dialogique comme GPT3.5 ou supérieur. Donc je vais mettre de coté une éventuelle AGI pour regarder en quoi ce que nous avons aujourd’hui est important, et notamment les questions suivantes:
- Est-ce que les modèles génératifs sont rendus assez fiables pour répondre à leur objectif d’interfaçage avec l’humain via le langage?
- Et si oui, quelle adoption peut-on envisager?
Une interface fiable?
Mes tests et ceux réalisés par des personnes autour de moi me font dire qu’il s’agit d’une interface avec une fiabilité plus élevée que je le pensais et surtout en progression assez rapide.
À titre d’exemple, je vous renvoie aux tests que j’ai documenté concernant le code de sécurité routière (CSR). À travers différentes méthodes, j’ai testé GPT3 “de base”, “fine-tuné” puis la version “3.5-turbo” avec du contexte supplémentaire. Et la progression entre chaque itération est marquée et je n’ai pas testé GPT4. Pour donner une évaluation plus qualitative, GPT3.5 n’était probablement pas au niveau d’un expert en droit pour comprendre une question et fournir une réponse complète, toutefois il était probablement meilleur qu’un quidam moyen tentant de comprendre le CSR et ses tournures parfois alambiquées. Fait majeur à mes yeux: les questions que je posais (souvent imprécises) et les réponses de GPT mettaient pleinement en lumière la nécessité d’une approche dialogique (i.e sous-questionner, préciser des éléments de questions, etc.), comme quand on discute avec une personne qui connait mieux un sujet que nous.
Je souligne qu’ici je mettais principalement en test les fonctions 1 et 2 (génération et interprétation). Mes tests consistaient en effet à fournir le CSR à GPT et à l’amener à formuler une réponse à une question; donc à utiliser ses fonctions d’intégration de contenu et de production de contenu en fonction de questions spécifiques. Je ne faisais nul appel à sa fonction 3 (connaissance générale); j’ai même vérifié avec un certain succès que si GPT ne trouvait pas la réponse à la question dans le CSR, il devait répondre qu’il ne savait pas plutôt que d’utiliser sa connaissance générale, souvent erronée, sur le sujet.
Bref, je le mettrais dans une zone de fiabilité acceptable pour interpréter et produire du langage humain lié à des tâches non critiques. Cela signifie qu’en lui fournissant l’information pertinente, dans des conditions où il n’y aurait pas de décision critique à prendre, un outil comme GPT serait capable de comprendre des instructions et fournir des réponses adéquates suffisamment souvent pour s’y fier. Évidemment, ma définition de « non critique » est floue et serait à préciser. De même, plus de tests seraient nécessaires pour tester la fiabilité, car la progression va surement ressembler à une courbe logarithmique; plus le temps passe, plus les améliorations deviennent difficiles.
Cette première série de tests permet d’évaluer un échange entre humain et machine, mais seulement avec un type de machinerie: le modèle dialogique lui-même, dont la caractéristique est justement de traiter du texte.
Mon second test consistait donc à évaluer si un modèle dialogique comme GPT peut être l’interface entre un humain et d’autres processus informatiques, par exemple un outil de gestion des courriels comme Gmail. Et là aussi, la réponse est un oui, tiède, mais réel. GPT est capable d’interpréter des données dans des formats structurés comme JSON et aussi de produire ce même format sur base de demandes formulées en français. Ce faisant, GPT, complémenté d’un script d’interfaçage (middleware), est capable de jouer un rôle d’interface passablement fiable entre une demande en langage naturel et une action d’un autre système informatique.
Ce second aspect a des conséquences majeures: si on considère GPT comme vivant dans un monde clos, sa capacité est assez limitée: tout doit passer par du langage humain que les humains maitrisent bien, mais pas les autres programmes informatiques. En étant capable d’utiliser les langages structurés propres à l’informatique, soudainement beaucoup des limitations de ChatGPT tombent. Deux exemples:
- Évidemment l’intégration Bing + GPT, qui permet de dépasser l’incapacité de GPT à connaitre des données postérieures à son entrainement (et son incapacité à citer des sources correctement);
- Le second est l’intégration de GPT avec la plateforme Wolfram. Ici, GPT devient capable d’échanger avec une plateforme ayant des capacités qui manquent à GPT, notamment en matière de calcul et d’accès à certaines informations.
Je vous invite à lire le billet complet de Stephen Wolfram, mais il met de l’avant non seulement que GPT peut s’interfacer avec des systèmes externes, mais qu’il peut même dialoguer avec ces systèmes s’ils sont prévus pour. Plus que cela: dans un exemple, ChatGPT reçoit une erreur de la plateforme Wolfram, interprète l’erreur et modifie sa requête avec succès pour obtenir la bonne réponse. Comme l’explique Stephen Wolfram, la fiabilité n’est pas toujours au rendez-vous et ChatGPT est parfois imprévisible, mais la fenêtre de possibilité que ce genre de comportement ouvre est assez impressionnante.
Ces cas d’usage sont loin de l’agent conversationnel omniscient, affabulateur et vivant dans sa bulle. Au contraire, il est possible, en lui fournissant la bonne information, de le rendre relativement fiable et “ouvert sur le monde” (à défaut que OpenAI soit ouvert sur les données ayant servi aux étapes d’entrainement de GPT.) Comprendre ces éléments me semble fondamental pour avoir des discussions plus riches sur ces modèles plutôt que de continuer à pointer les anecdotes d’erreurs grossières ou de belles surprises.
Hype et adoption
Plusieurs l’ont pointé, les modèles génératifs rappellent de mauvais souvenirs: que ce soit les crypto récemment, ou encore les voitures autonomes il y a un peu plus longtemps, autant de technologies qui devaient révolutionner la surface de la Terre du jour au lendemain et dont on attend encore le grand soir (quand ça n’a pas été un flop monumental). Comme beaucoup de technologies, c’est un cas assez classique: une “solution” se cherchant un problème. Et la littérature sur le sujet est assez abondante.
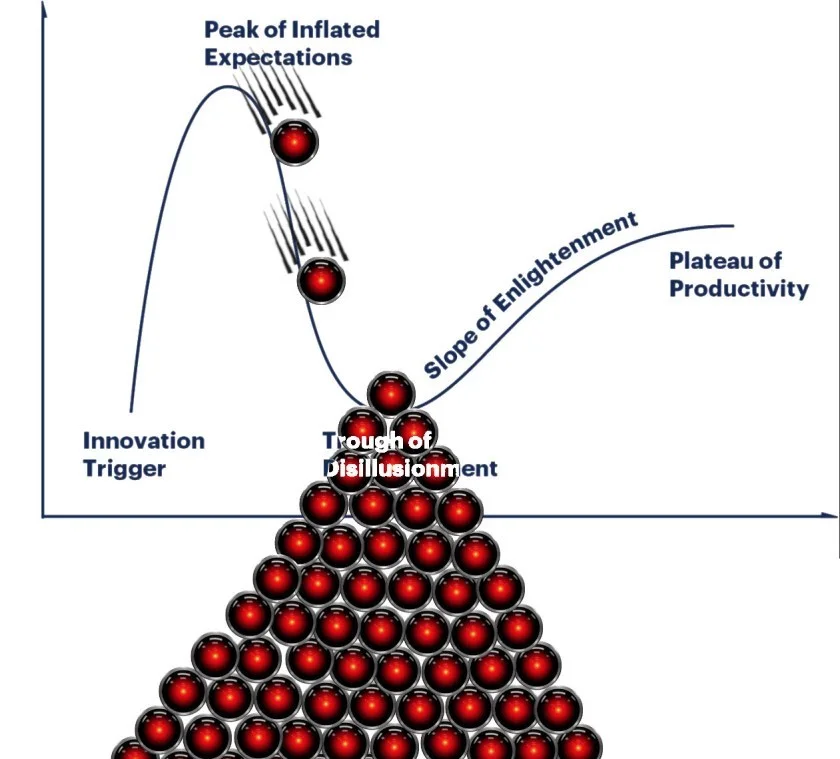
De manière pratico-pratique, cette dynamique est bien décrite par le Gartner Hype Cycle, un cycle typique par lequel passent la majorité des technologies prometteuses: une phase d’espoir et de promesses inatteignables connue comme le Pic des attentes démesurées suivie d’une phase de déception et d’échecs, parfois liée au manque de maturité de la technologie, mais aussi à l’exagération des espoirs et à l’incapacité à trouve une adéquation réelle avec les cas d’usage anticipé. Cette phase est connue comme le Creux de la désillusion. Éventuellement, la technologie finit par trouver sa place, ses cas d’usage et une normalisation de sa présence.
Le cycle canonique cache tout de même des variations; par exemple certaines technologies restent coincées dans l’enfer du Creux, n’en sortent que très lentement ou simplement retournent au début du cycle. L’envergure du plateau d’adoption est aussi sujette à variation: alors que certaines technologies finissent par rejoindre voire dépasser les espoirs initiaux (pensons au Web), d’autres ne restent qu’une pale copie des espoirs suscités. Différentes saveurs de ce qu’on nomme globalement intelligence artificielle sont déjà passées au travers de ce cycle avec plus ou moins de succès. Les modèles dialogiques sont une nouvelle saveur et on peut facilement les placer bien haut sur le Pic des attentes démesurées: la voie est pavée pour des déceptions.
Où va-t-on à partir de là? Je n’ai pas de boule de cristal pour prédire comment les modèles dialogiques vont évoluer dans ce cycle. Je me permets quand même quelques remarques venant de ce qu’on sait de technologies passées.
La première, c’est que la vitesse de développement ou d’amélioration d’une technologie ne sont pas des facteurs prédictifs pour la vitesse d’adoption. L’adoption d’une technologie dépend d’une foule de facteurs, au premier rang desquels la présence d’une série d’infrastructures nécessaires. Le web en 1998 avait vaguement tout ce qu’il fallait pour permettre des services numériques comme ceux que nous avons aujourd’hui. Pour rendre tout cela faisable, il manquait des infrastructures technologiques physiques comme des réseaux à forte capacité ou encore des bibliothèques et packages de programmes qui s’assemblent comme des Lego pour monter des services numériques à un coût raisonnable. Tous les services en ligne que nous connaissons reposent sur une quantité faramineuse de logiciels libres, souvent développés entre compétiteurs (logique de coopétition). Exemple: dans le domaine du Deep Learning, une bonne partie des progrès sont rapidement intégrés à des bibliothèques ouvertes comme PyTorch qui bénéficie de l’appui d’acteurs par ailleurs concurrents (Amazon, Google, Meta, AMD ou encore NVidia).
Souvent, il faut aussi des infrastructures physiques non technologiques, par exemple un Amazon ne pouvait atteindre sa véritable hégémonie qu’avec des services de livraison adéquats. Pour avoir travaillé dans une entreprise de livraison pour la vente par correspondance en 2000-2001, les délais de livraison étaient de 5 jours… non garantis, et pour des volumes assez faibles. Une situation incompatible avec les besoins d’Amazon.
Un autre facteur majeur est que la croissance de l’adoption est influencée par… l’adoption existante. C’est l’effet de réseau qui comprend notamment la normalisation de certains comportements. Exemple: avoir le réflexe de faire ses achats en ligne plutôt que de se déplacer, ou streamer la musique plutôt que détenir un support physique ou numérique, ou encore, pour les services aux entreprises, passer par un “marketplace” comme Amazon ou Etsy plutôt que de développer son propre canal de vente. Ces changements se font progressivement, mais plus du monde adopte… et plus du monde adopte.
Tous ces points combinés ont pour effet que l’adoption d’une technologie majeure se fait souvent plus lentement qu’attendu (d’où la phase de déception de Hype Cycle), mais vient souvent avec des effets plus profonds qu’anticipés. C’est ce que j’appelle la dimension rampante de l’innovation. Si on regarde la voiture, il a fallu quasiment 50 ans pour qu’on passe d’un stade d’une technologie relativement mature à un objet représentatif d’un mode de vie ancré, ayant changé les dynamiques sociales bien au-delà de simplement changer de véhicule: la voiture a changé notre perception de l’espace et du temps, a fait évoluer la forme physique des villes et des pays, influençant au passage la santé et l’éducation des populations. Un trait commun des technologies ayant eu un succès très large, les technologies transformatrices, est lié à leur capacité à reconfigurer, de manière parfois difficilement perceptible, la vie d’une large partie de la population. Un jour on se dit qu’Internet est une technologie disruptive, émancipatrice et décentralisatrice, puis le lendemain on se réveille en constatant que c’est un outil de surveillance et de contrôle centralisateur favorisant la polarisation et la déstabilisation (j’exagère à dessein). Je lis déjà des analyses « GPT va change comment XYZ se fait d’ici 12 mois, 18 mois » etc. Il est très tôt pour se prononcer sur la vitesse de déploiement. A priori, le déploiement des modèles dialogiques nécessite peu d’infrastructures et les changements d’usage ne sont peut-être pas aussi nombreux qu’on le croit. En revanche, la question de la fiabilité pourrait demeurer un frein notable. Pour ce qui est de l’aspect transformationnel, là aussi il est tôt pour voir poindre les traces de changements aussi profonds.
Accélération des cycles d’adoption
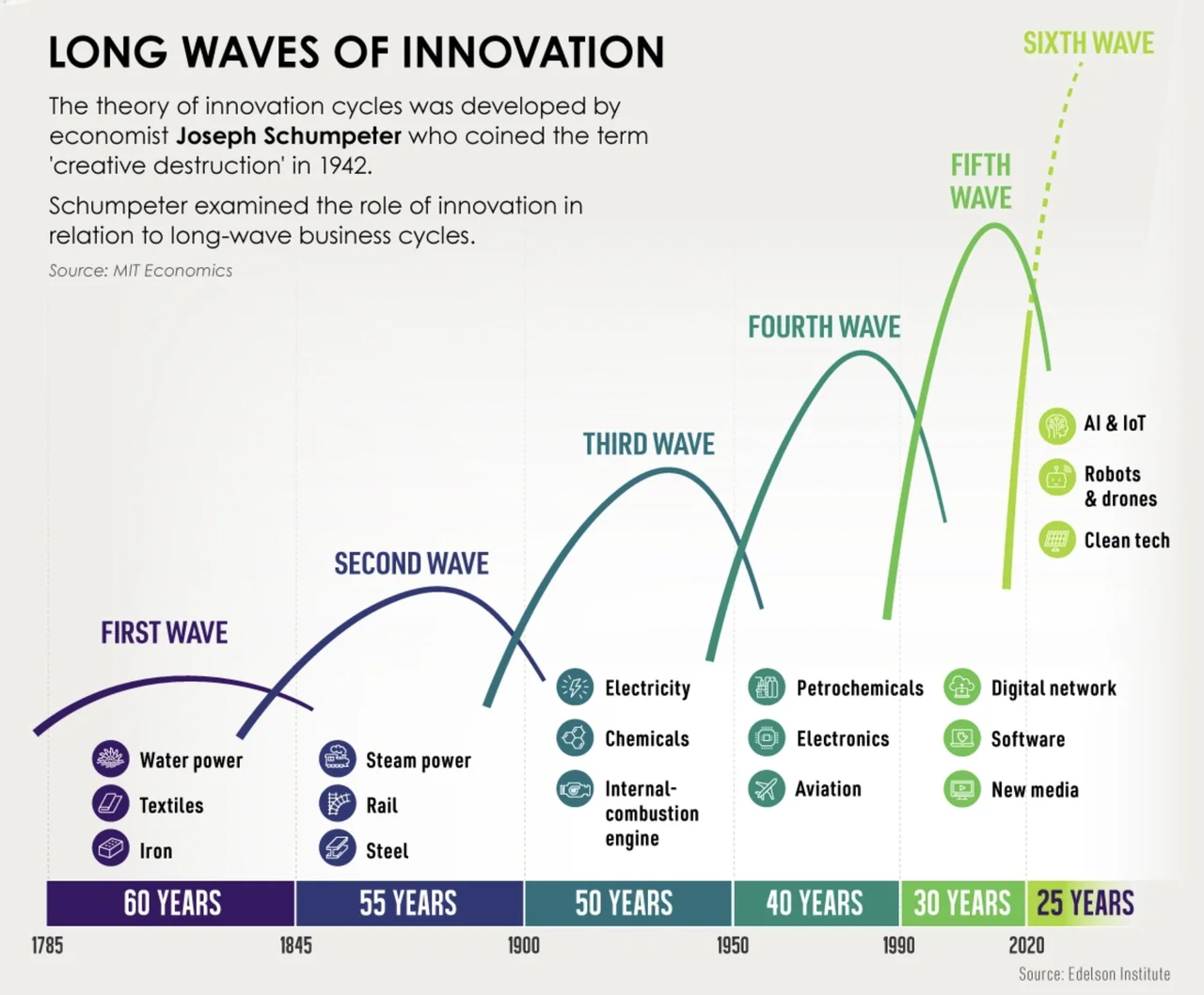
Même si les technologies mettent souvent plus de temps qu’on imagine être adopté, les cycles d’adoption tendent à se réduire. En effet, une nouvelle technologie majeure vient rarement seule: de par les progrès scientifiques, du fait des brèches créées par une nouvelle technologie, une série d’innovations vont apparaitre de manière assez concomitante pour se combiner en un cycle plus grand, sous forme de révolutions industrielles ou de cycles industriels. Et ces cycles vont en s’accélérant. Plusieurs phénomènes sont liés à cette accélération, notamment le fait que les technologies des derniers cycles ont besoin d’infrastructures moins lourdes. On note aussi une professionnalisation de l’innovation. Depuis Schumpeter au milieu du XXe siècle, l’innovation est devenue une valeur positive que l’on peut inciter; et les gouvernements investissent et se structurent pour produire plus d’innovation sur leur territoire. Cette notion de cycle est une simplification de la réalité et plusieurs études soulignent les limites de cette simplification, mais dans le cadre de mon propos, c’est suffisant.
Les deux dernières décennies ont vu l’émergence d’un écosystème structuré d’accompagnement des entreprises porteuses de technologies ou de modèles d’affaire de rupture et à fort potentiel de croissance, les fameuses startups. Maintenant, à peu près n’importe où sur Terre, et notamment dans l’entourage des universités, est accessible un concentré de substrat à startup allant de l’aide à la détection d’opportunités, à la définition du modèle d’affaire en passant par la stratégie de propriété intellectuelle et aboutissant, évidemment, par des financements majeurs. Même si la Silicon Valley en demeure le mètre étalon et le centre gravitationnel, l’aventure peut se tenter partout.
Avec ces écosystèmes se sont développés des mécanismes, des patrons d’accélération dans la recherche de mise en application de technologies novatrices, la fameuse capacité à trouver un problème correspondant à une technologie. Plus une technologie est généraliste, applicable à de nombreux cas d’usages, et plus, paradoxalement, il peut être difficile de trouver une application concrète, surtout pour une entreprise travaillant seule et donc avec des moyens limités. OpenAI a donc pleinement tiré parti de patrons d’accélération connus. En voici quelques exemples:
- Partenariat avec une grande entreprise bien installée, et ayant un intérêt potentiel dans la technologie, en l’occurrence Microsoft. Ce genre de partenariat permet d’avoir accès à des financements, à des infrastructures technologiques ainsi qu’à une puissance de frappe en matière de mise en marché. OpenAI a très tôt bénéficié d’investissements dépassant le 1G$ (maintenant surement plus de 10G$), dont un accès à des infrastructures “infonuagiques” (Azure); Microsoft est aussi un partenaire idéal pour trouver des cas d’application comme on le voit déjà avec l’intégration de GPT à Bing et Office.
- Bien qu’étant relativement jeune, OpenAI se lance dans le financement de startups… utilisant leur technologie. L’idée étant d’aider à faire croitre des entreprises qui pourraient être de futurs bons clients ou encore des idées de mise en marché prête à être rachetées. En d’autres termes, OpenAI crée son marché!
- Dès le début, OpenAI a rendu une bonne partie de ses produits disponibles via des API, c’est-à-dire intégrable dans d’autres outils informatiques. C’est à travers des API que des Twitter de ce monde se sont développés, les produits d’Amazon et de Google reposent fortement sur leur capacité à s’intégrer via des API. Alors que les autres entreprises qui ont développé certains modèles (dialogique ou non) les ont conservés de manière interne pour en faire un avantage compétitif, OpenAI s’est positionné comme fournisseur d’un service pouvant être intégré dans d’autres produits et services.
- Dans la même veine, OpenAI permet de développer des extensions à ChatGPT, permettant d’ajouter facilement des fonctionnalités externes à leur modèle; c’est la manière dont a procédé Wolfram (exemple ci-haut) pour ajouter des capacités de calcul avancé à ChatGPT. Là aussi, c’est un moyen peu coûteux pour OpenAI de découvrir des améliorations ou des cas d’usage à fort potentiels.
- Enfin, une bonne stratégie de mise en marché. Personnellement, j’ai du mal à croire la légende voulant que OpenAI tentait un coup de poker en lançant ChatGPT. Évidemment sur Internet, la viralité n’est jamais garantie, mais après le succès d’estime de DALL-E, ils ne pouvaient pas ignorer l’intérêt que cela susciterait. Bref, en activant la pompe à hype, OpenAI a accéléré, catalysé les autres patrons d’accélérations en incitant un maximum d’acteurs à sauter dans la danse, même si c’est des compétiteurs comme Google. Le hype est la proverbiale marée capitaliste qui fait monter tous les bateaux… sauf que certains sont mieux préparés pour en tirer parti.
Tout cela mis ensemble offre une capacité de dissémination de leur technologie sans pareil. En d’autres termes, OpenAI a utilisé quasiment toutes les méthodes disponibles pour accélérer la découverte de cas d’usage et de modèles d’affaires viables tout en s’assurant la mobilisation d’investissements sans précédent pour leur domaine d’affaires. Avec une stratégie quand même assez brillante (bien que possiblement chanceuse), OpenAI s’est même sorti de la nécessité de se trouver des cas d’usage pour vivre. Bien que ChatGPT soit accessible de manière payante, le gros des revenus ne viendra probablement pas de ChatGPT, dont le rôle est avant tout d’être un sémaphore orientant la ruée vers l’or. Parmi tous les chercheurs d’or, certains vont trouver des modèles d’affaires viables sur lesquels OpenAI va se contenter de faire payer l’accès à des modèles de plus en plus puissants, spécialisés ou performants.
Parlant de faire payer: une condition sine qua none pour une adoption de masse c’est une structure de coût adaptée. Si plusieurs ont souligné les coûts (humains, financiers et environnementaux) exorbitants de ces modèles, il est important de se rappeler que la technologie est encore à ses balbutiements et le potentiel d’optimisation est probablement énorme. Pour l’accès en API, qui est payant depuis le début, le passage du meilleur modèle de la version 3 à la version 3.5-turbo de GPT, s’est fait en divisant par 10 le prix tout en produisant de meilleurs résultats et plus vite.
Un modèle comme Stable Diffusion a été optimisé au point de pouvoir fonctionner sur un laptop. Enfin, chaque nouvelle version de modèle comme Midjourney ou GPT amène des améliorations notables. En d’autres termes, on est très loin d’avoir vu la fin des améliorations de ces modèles, qu’il s’agisse de performance ou de coût.
Petit détour par l’AGI
Artificial general intelligence ou encore AGI. C’est ce qui fait rêver Sam Altam, P.-D.G d’OpenAI; c’est aussi ce qui inquiète des personnes aussi diverses que Elon Musk ou Yuval Hariri, qui y voient un risque existentiel pour l’humanité. Personne n’est vraiment capable de définir ce qu’est une AGI (ou plutôt, chacun a sa définition plus ou moins précise). Des chercheurs de Microsoft ont publié récemment une recherche soulignant que GPT4 démontrait des “étincelles” d’AGI, ils ont défini cela en faisant passer au modèle une série de tests de connaissance. À la limite, le plus intéressant dans l’article est la litanie de compétence manquant à GPT4.
Personnellement, je ne comprends pas cette volonté de créer une AGI; la perspective d’avoir une bonne interface humain-machine, fiable, est déjà quelque chose de potentiellement immense. La monomanie à vouloir spécifiquement reproduire les fonctions cognitives humaines a quelque chose de troublant.
Par ailleurs, de mon point de vue, la question n’est pas de savoir si un modèle atteint le stade indéfinissable d’AGI, mais plus de savoir les moyens que l’on donne aux modèles existants pour agir sur leur entourage. Depuis longtemps, des agents conversationnels peuvent agir sur des humains en tenant de propos dérangeants ou challengeant et avec les nouveaux modèles conversationnels, cette capacité a beaucoup augmenté; le geste tragique d’un homme belge est un gros voyant rouge qui clignote . Comme je l’ai expliqué plus haut, les capacités de GPT lui permettent d’agir sur le monde extérieur: ce qui est possible avec GMail ou la plateforme Wolfram l’est aussi avec une maison connectée ou un véhicule connecté et pourquoi pas des armes.
Enfin, comme viennent de le démontrer des chercheurs de Stanford, GPT peut crédiblement incarner des personnages fictifs et pas mal autonomes. En donnant les bonnes instructions, en créant les bonnes conditions, GPT complémenté par d’autres programmes plus classiques, peut créer un simulacre d’agentivité humaine. En mettant tout ceci ensemble, ma conclusion est que nous déjà les pièces nécessaires peut-être pas pour atteindre l’AGI, mais à tout le moins pour produire des simulacres humains capables d’action dans l’environnement réel. Bref, la question ne se pose pas tant en comparant pied à pied chaque compétence d’un modèle avec celle d’un humain, c’est plus de se demander quel est le degré d’autonome et d’action d’un modèle (donc sa capacité de nuisance). Si ChatGPT tel qu’il est mise en scène ne suscite pas de crainte imminente, GPT, une fois largement intégré à d’autres outils et « prompté » adéquatement est en mesure de faire beaucoup de choses et de manière quasi-autonome.
Flop? Adoption lente? Adoption rapide?
Alors, avec tout cela, quelle adoption envisager pour des modèles dialogiques? Quelle sera l’envergure des conséquences? Est-ce que la technologie va rester dans le Creux de la désillusion et vivre ainsi un n-ième hiver de l’intelligence artificielle ou va-t-on voir ce genre de technologie pulluler rapidement?
Je n’ai pas de boule de crystal, mais j’aurais tendance à voir une adoption significative mais plus lente qu’on veut bien le croire. Oui, plusieurs personnes ont déjà adopté ChatGPT comme une sorte d’assistant; toutefois ça semble être assez superficiel. Actuellement, en mode agent conversationnel omniscient, la fiabilité n’est pas au rendez-vous et il faut réfléchir à deux fois avant d’en accepter les réponses. De même, l’intégration au sein d’outils comme MS Office va surement permettre une certaine normalisation de l’usage de ce genre d’outil ainsi que des gains de productivité, mais j’ai l’intuition que ça ne sera pas nécessairement si transformatifs.
Les transformations plus profondes vont surement se faire via l’intégration à des outils ou des plateformes de manière parfois moins visible. Dans un premier temps, parce que la fiabilité n’est pas garantie, ces outils risquent d’être utilisés dans des conditions spécifiques, parfois même en arrière-plan et sur des processus peu critique. Progressivement, à mesure que ces outils vont gagner en fiabilité, ils vont gagner une place plus importante, plus visible. À ce stade-ci, il est très difficile de dire où les percées pourraient se faire sentir en premier… dans un contexte où on ne sait pas si on va réussir à atteindre une fiabilité raisonnable pour la majorité des cas envisagés (pensons aux véhicules autonomes où il fut assez rapide de répondre à ce qui représente 90% des situations courantes, mais le 10% restant s’avère extrêment difficile à gérer.)
Si la fiabilité est au rendez-vous, la question va être de savoir si on va voir une intégration dans les normes sociales et donc une modification de ces dernières. Beaucoup de personnes sont déjà à l’aise de parler à Alexa ou à leur cellulaire, donc une partie du changement est déjà présent. Je lis plusieurs critiques dire qu’ils ne veulent pas lire ou regarder des contenus “synthétiques”; que le langage humain est porteur de sens, d’intention et de toutes ces choses que les machines ne peuvent pas avoir. Le langage est déjà largement utilisé comme un outil froid et sans profondeur. Parfois, quand je lis les courriels de ma boite de réception et j’ai du mal à imaginer qu’une personne a pu écrire ça, qu’il puisse y avoir une quelconque intention si ce n’est suivre des procédures.
En d’autres termes, j’ai l’impression qu’à bien des égards, nos modes de communications ont suffisamment amené le langage sur le terrain de la simple fonction transactionnelle pour que des modèles dialogiques puissent parfaitement s’y insérer sans être choquant. Je ne parle pas de la grande littérature mais des échanges de tous les jours qui représentent surement 99% des écrits (ou paroles) produits actuellement. Du moment qu’ils interprêtent correctement un texte et agissent de manière conséquente, suffisamment de personnes et d’entreprises seront heureuses de leur donner un rôle si ça permet d’être plus efficace.
Les agents conversationnels démontrent d’ores et déjà une capacité à avoir une autonomie, une fois intégré avec d’autres outils qui peuvent les aider à agir. J’ai entendu à quelques reprises des personnes dire que ces modèles génératifs ne sont rien sans un input humain (le prompt). Ça me semble partiellement faux. Le sous-entendu de cette affirmation et qu’il faut toujours un huain pour “relancer” la discussion. Un modèle dialogique peut recevoir quotidiennement un prompt automatisé et en faire autre chose. Connecté à d’autres systèmes, il peut “décider” de réaliser une action ou une autre (toujours s’il est supplémenté par un outil que le connecte à d’autres systèmes informatiques). Ce n’est pas de la science fiction, c’est avéré. Et j’ai du mal à imaginer que personne ne va exploiter cette capacité.
C’est pourquoi, j’en viens au premier bloc de mon titre: les modèles dialogiques risquent d’amener beaucoup de changement. Non pas que ce soit une technologie aidant à rélever des défis importants, mais elle répond à un besoin présent depuis de nombreuses années: interprêter du contenu textuel, service d’interface humain-machine, produire du contenu textuel accessible pour un humain, etc. Et offre aussi des capacités qui dépasent la simple interprétation. La mise en oeuvre généraliste et omnisciente de ChatGPT souffre d’une fiabilité qui limite, à mes yeux, sa capacité d’adoption à court terme. Des mises en oeuvre spécialisées, surtout connectées à d’autres outils, pourraient elles être capables d’atteindre une certaine fiabilité pour des tâches plus spécifique. Même si cette technologie doit encore passer à travers son Creux de la désillusion, à moins qu’elle frappe un mur, une limite de fiabilité par exemple, j’ai du mal à voir comment elle ne s’insérerait pas progressivement dans la société, certes en la changeant mais sans réellement changer la trajectoire d’ensemble; ce sera l’objet de la seconde partie.