Dernière exploration avec GPT: est-il possible d’interfacer un modèle de langage (LLM) avec des outils logiciels existants, par exemple pour envoyer des courriels? Et d’ailleurs pourquoi?
Démontrer ad nauseam que les connaissances générales de GPT ne sont pas si bonnes ou qu’il est facile de lui faire dire n’importe quoi et son contraire, tout cela fait que l’on passe à côté d’une réelle compréhension de ce genre d’outil et donc de son impact possible. Le fait que GPT fasse preuve d’une certaine “culture générale” mâtinée d’une tendance à l’affabulation est un bénéfice secondaire.
La fonction première de ces modèles est celle d’interprétation du “langage naturel”. Cette fonction d’interprétation du langage est ce qui fait défaut aux outils informatiques depuis des lunes; barrière qui, une fois éliminée, permettrait de s’affranchir du symbolisme actuellement nécessaire et représenté par des interfaces d’utilisation contraignantes.
Sauf que pour être en mesure de s’affranchir réellement de cette barrière, il faut que les LLM soient capables de faire le pont: comprendre d’un côté le langage humain et être capable de l’autre côté d’utiliser du langage “machine”, suivant un certain formalisme, pour transformer le verbe en action (informatique).
GPT démontre d’ores et déjà cette capacité: la version Copilot qui permet de générer du code est en exemple. L’intégration avec Bing pour faire un moteur de recherche assisté en est une autre. Toutefois, je voulais tester moi-même comment cela pourrait fonctionner. Mon précédent test sur le code de sécurité routière (billet 1 et 2) visait à tester la capacité de traitement et d’interprétation de GPT sur des volumes d’information supérieurs à sa fenêtre de contexte, ici, je cherche à évaluer la capacité du modèle de langage à jouer le rôle d’interface d’interprétation humain-machine.
Commande vocale pour courriel
Mon défi: était-il possible de passer une commande vocale instruisant Gmail d’envoyer un courriel?
Les blocs Lego utilisés pour l’occasion:
- Une interface me permettant d’envoyer des messages vocaux, de récupérer ces messages vocaux dans un script de ma conception (via une API) et de renvoyer des réponses écrites à l’utilisateur. J’étais parti pour utiliser Discord, mais ça ne marchait pas à mon goût. En donnant mes contraintes à ChatGPT, il m’a conseillé Telegram qui s’est avéré effectivement un très bon choix.
- Un outil parole-vers-texte, là aussi pouvant être appelé par script/API, en l’occurrence le module Whisper API d’OpenAI
- Évidemment GPT et Gmail, les deux offrant là aussi des API pour être contrôlés par un script. Je m’étais fixé un objectif supplémentaire: avoir un mécanisme modulaire qui serait capable de recevoir d’autres commandes de manière flexible: par exemple, créer des événements dans un agenda, gérer des tâches, etc. J’ai donc mis en place un mécanisme de recette: un fichier de configuration définit l’ensemble des étapes et des fonctions à appeler pour réaliser une tâche particulière.
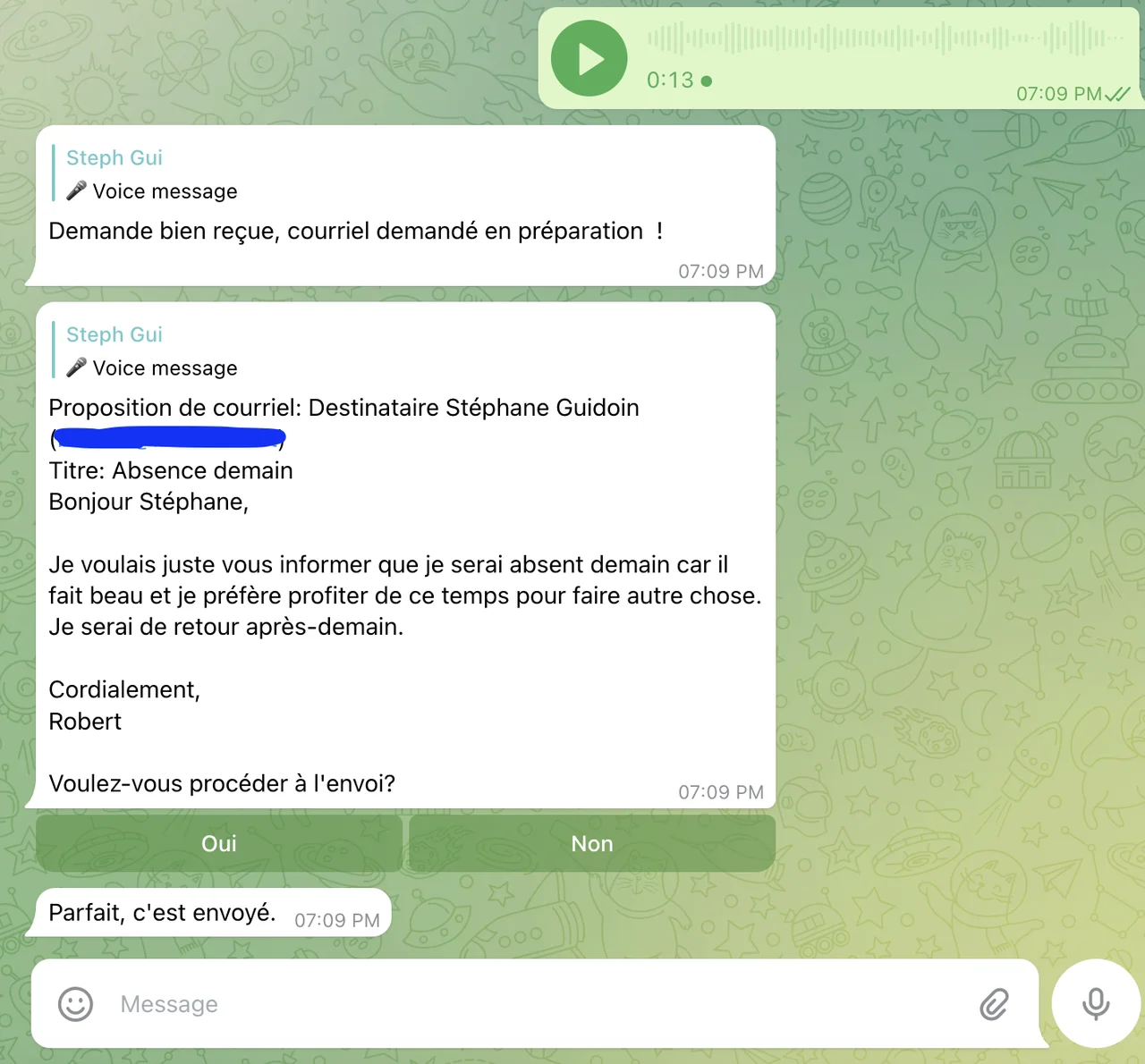
Résultat net: un succès, avec quelques bémols. Ci-dessous une capture d’écran montrant l’échange sur l’interface web de Telegram.
Le déclencheur de la séquence est un message vocal qui va comme suit (ceci est exactement la chaîne de caractère produite par Whisper): « Est-ce que tu peux écrire un courriel à Stéphane Guidoin pour lui dire que demain je ne rentrerai pas au travail, car il fait trop beau pour travailler. Je rentrerai après demain. Signé Robert. »
Comment ça marche
Pour les curieux, une section méthodologie à la fin rentre plus dans le détail (et présente quelques limites). Tout commence par un fichier de configuration qui contient les recettes. Le fichier décrit ce que chaque recette est capable de faire ainsi que les étapes pour la réaliser. Ensuite, j’ai créé un bot Telegram, lequel est contrôlé par mon script Python.
Lorsque l’usager envoie un message vocal au bot, le fichier son est reçu par mon script qui l’envoie à Whisper API, ce dernier générant une transcription en texte. La transcription est envoyée à GPT conjointement avec une liste contenant les noms et descriptions des recettes et une instruction: retourner le nom de la recette correspondant à la demande de l’utilisateur. Pour rendre le tout facilement utilisable par mon script Python -et c’est la clé de la démarche, je demande à GPT d’utiliser en guise de réponse le format descriptif JSON. Ça prend le format {"nom_recette": "send_mail"}
Une fois la recette sélectionnée, une confirmation est envoyée à l’utilisateur via Telegram et le script va ensuite s’en tenir à suivre les étapes de la recette, à savoir une alternance de requêtes à GPT et de fonctions auprès d’autres services, Gmail dans ce cas-ci. Les requêtes GPT sont entièrement décrites dans le fichier de configuration, les fonctions Gmail sont nommées dans le fichier de configuration, mais doivent évidemment être codées. La recette pour l’envoi de courriel ressemble à ceci:
- La requête de l’utilisateur est envoyée à GPT avec l’instruction de retourner le nom du ou des destinataires, là encore en retournant les résultats au format JSON;
- Les noms des destinataires sont envoyés à Gmail pour récupérer les adresses courriel;
- La requête de l’utilisateur est de nouveau envoyée à GPT avec l’instruction, cette fois-ci, de générer un titre et un contenu de courriel;
- Mon script produit un brouillon de courriel qui est envoyé à l’utilisateur via Telegram pour confirmation;
- Sur approbation de l’utilisateur, grâce un bouton oui/non, le courriel est envoyé.
Est-ce que ça marche?
Ça fonctionne étonnamment bien, considérant que mon code ferait sûrement hurler un vrai développeur. De manière générale, GPT interprète de manière fiable les requêtes. Quand on lui fournit un canevas de réponse (ici une structure JSON avec des trous à remplir), il comprend toujours comment faire. Sur des dizaines d’essai, il a toujours bien procédé. Tel qu’expliqué dans la méthodologie, il a juste fallu que je gère les excès verbomoteurs de GPT.
Je dois dire que Whisper API m’a aussi impressionné pour la transcription: à peu près pas d’erreur, il ôte les onomatopées diverses et variées et autres hésitations et arrive même à bien épeler la majorité des noms de famille.
Mon produit est loin d’être « production ready », mais les quelques heures que j’ai passé dessus m’ont confirmé ce dont j’avais l’impression: la capacité de GPT à interpréter les demandes fait des LLM un candidat vraiment sérieux pour servir d’interface flexible. Vous me direz que Siri, Alexa et autres font déjà cela. C’est en partie vrai: Siri et Alexa font plus d’erreurs (à mes yeux) et surtout ce sont des systèmes pour lesquels il est plus difficile de s’intégrer. Ici, il est possible de faire des intégrations multiples et jusqu’à un certain point de contrôler ces intégrations. Nombre de plateformes proposent d’ores et déjà des fonctionnalités “AI-improved” et cela va sûrement exploser dans les prochains mois.
Évidemment, reste la question de la réelle fiabilité de la chose. C’est à travers des intégrations à grand volume qu’il sera possible d’évaluer réellement si la fiabilité est de l’ordre de 99% ou de 90%, la différence entre un bidule perçu comme fiable ou pas fiable.
Dernier commentaire de fond: jusqu’à un certain point, en expliquant les règles du jeu à GPT, il serait capable de générer des recettes. En lui fournissant comme exemple ma recette, je lui ai demandé de faire de même pour créer une tâche Asana; il m’a fourni une réponse qui se tenait. De la même manière, ici je me limite à envoyer un courriel à partir de zéro, mais il serait possible de répondre à un courriel. De manière plus générale, la même approche pourrait être utilisée pour faire une synthèse des courriels d’une journée, faire ressortir les courriels qui semblent nécessiter une action urgente et y répondre, etc.
Méthodologie et commentaires techniques
Tel que mentionné, le principal point où GPT manquait de constance et de prévisibilité pour servir de pont humain-machine est cette tendance à être inutilement verbeux et à fournir une réponse du type
Voici la structure JSON répondant à votre requête:
{"recette": "send_mail"}
Alors que l’on voudrait simplement la structure JSON. J’ai contourné le problème avec une expression régulière, mais c’est… bof bof. L’exemple de Copilot montre toutefois que lorsqu’entrainé dans cet objectif, un LLM est capable de s’en tenir à des formats structurés.
L’autre enjeu dans ce cas d’usage est la manière d’épeler les noms de famille. À ma surprise, Whisper avait la majorité des noms de famille correctement. Mais quand il les manquait, je n’ai pas trouvé de manière fiable de faire comprendre à GPT que si je lui donnais une série de lettres après le nom de famille, ça disait comme épeler le nom. Par ailleurs, l’API de Gmail n’est pas très tolérante aux fautes d’orthographe quand on cherche un nom, donc récupérer une adresse courriel avec une erreur dans le nom ne marche pas. C’est la principale limite, insurmontée à ce stade, dans ma démarche.
Whisper API supporte uniquement des messages d’une minute. Il existe évidemment des approches pour segmenter un fichier audio et le transcrire en plusieurs morceaux, toutefois je n’ai pas implémenté cette fonction. Mes tests se sont donc limités sur des messages vocaux de moins d’une minute. Quoiqu’il en soit, dans la majorité de mes tests, GPT a suivi les consignes; que je lui demande un courriel court ou plus long, formel ou informel, tutoiement ou vouvoiement et autres permutations que j’ai tentées. La génération du titre du courriel laissait parfois à désirer, mais c’est mieux que beaucoup de titre de courriel que nous nous envoyons quotidiennement (quand il y a un titre…). Genre de petite limitation un peu dommage: GPT n’interprétait pas que quand je lui disais que le message allait à ma conjointe, il pouvait automatiquement sélectionner une formulation informelle et le tutoiement.
Je n’ai pas mis en place beaucoup de chemins alternatifs: si l’adresse courriel n’est pas trouvée, si l’utilisateur veut ajuster le brouillon, etc. Ça se ferait parfaitement, ça prenait du temps dont je ne disposais plus.
Tout cela est accompli avec environ 300 lignes de script Python et un fichier de configuration JSON d’une centaine de lignes. Je demeure impressionné par la facilité de mise en œuvre. Les deux tâches qui m’ont pris le plus de temps: corriger mon installation de Homebrew qui n’avait pas appréciée de passer sur une puce M1 et gérer les callbacks de l’API de Telegram. Le contrôle de Telegram se fait avec la librairie Telebot, tandis que pour Whisper, GPT et Gmail, j’utilise les librairies officielles. Le modèle utilisé pour GPT est gpt-3.5-turbo, je n’ai pas encore accès à GPT4 via l’API.