Le présent texte est un tutorie produit pour un atelier d’EcoHackMtl. Il vise à démontrer qu’il n’est pas nécessaire d’être un développeur ou d’avoir des compétences informatiques avancées pour faire de la visualisation des données géospatiales. Vous pouvez désormais essayer ces recettes dans le confort de votre chez vous.
Temps estimé: 20-30 minutes.
Sujet d’étude: liste exhaustive des arbres dans le domaine public (hors parcs) de l’arrondissement Ville-Marie à Montréal.
Objectif: Réaliser une carte élégante permettant de distinguer facilement la taille de l’arbre (diamètre du tronc) et les essences.
Niveau: Idéalement avoir déjà touché à du HTML ou à un autre langage descriptif ou alors aimer essayer des nouvelles choses sur votre ordinateur.
Seront considérés: Les outils Google Fusion Table et CartoDB, OpenRefine, les projections cartographiques et l’encodage de caractères.
Nettoyer les données
La première étape consiste à localiser les données nécessaires. En l’occurrence, les arbres sont de juridiction municipale, donc c’est sur le portail de la Ville de Montréal que cela se trouve. Téléchargez le fichier correspondant à l’arrondissement Ville-Marie et dézippez-le dans un répertoire de votre choix.
Avertissement préliminaire: le nettoyage des données n’est jamais pareil d’un jeu de données à un autre. Ici, nous allons présenter une manière de faire parmi d’autres et soulever quelques enjeux classiques.
OpenRefine (anciennement GoogleRefine) est un outil très pratique pour rapidement nettoyer des données. Téléchargez la version pour votre système d’exploitation, installez-la et lancez-la. Note: Cet outil est “web-based”, donc en le lançant, il va ouvrir votre navigateur internet (ou une nouvelle fenêtre dans votre navigateur) et l’ensemble du traitement se fera via votre navigateur.
Encodage de caractère
Une fois dans Open Refine:
- Ouvrez le fichier CSV des arbres de l’arrondissement Ville-Marie,
- Choisir un encodage de caractère (character encoding):
- Essayez “UTF-8” et regardez l’impact sur la prévisualisation des données, notamment là où se trouvent des caractères accentués.
- Ensuite essayez “ISO-8859-1”. Est-ce mieux?
- Cliquez sur “Create a project”.
Lorsque les données contiennent des caractères spéciaux (notamment accentués), le problème d’encodage des caractères est un classique. En général, il suffit de choisir le bon encodage et c’est bon: mais c’est important de bien le faire dès le début! Si vous partez avec un mauvais encodage, vous risquez de devoir y passer beaucoup de temps par la suite… Pour le français, les deux encodages classiques sont UTF8 qui peu représenter un très grand nombre de caractères ou ISO-8859-1 (également connu comme latin1) qui est spécifique aux langues latines.
Traitement des colonnes
Maintenant ouvrez le fichier CSV dans un éditeur de texte et regardez la taille du fichier: 20MB. Remarquez la présence de nombreux espaces inutiles. Inutiles et problématiques: un fichier plus gros est plus long à traiter. Des espaces surnuméraires peuvent également causer toutes sortes de problèmes lors de l’analyse des données. En l’occurrence, dans une étapes subséquence (CartoDB), la limite de taille sera de 5MB!
Heureusement, Open Refine a la solution:
- Premièrement, en regardant dans le preview d’Open Refine, on note que la dernière colonne est toujours vide (mais en fait remplie d’espaces). Il faut donc supprimer cette colonne: cliquez sur le titre de la colonne puis edit column et remove column.
- Deuxièmement, les noms de rue contiennent également des espaces inutiles. Dans la colonne “rue”, faites un clic-droit sur le titre de la colonne puis, edit cell, common transformation et finalement remove trailing white spaces.
L’air de rien, vous venez de grandement améliorer la qualité de votre jeu de données.
Maintenant, exportez le projet en mode comma separated value. Regardez le fichier dans votre navigateur de fichier: il fait désormais 1.8MB! Un gain de 90%!
Visualisation avec Google Fusion Table
Google Fusion Tables (GFT) est l’outil par défaut pour beaucoup de personnes souhaitant “mettre des points sur une carte”. Bien qu’il soit très facile d’accès, il n’est pas toujours évident d’obtenir le résultat esthétique souhaité sans recourir à du développement logiciel.
Créez un compte Google si vous n’en avez pas et rendez-vous à l’adresse de Google fusion table.
Attention: ici nous avons un problème! Le fichier fournit par la Ville ne contient pas des latitude/longitude comme GFT les supporte (sujet sur lequel nous reviondrons plus bas). Pour l’heure, prenez juste le fichier suivant qui contient des latitude/longitude: le fichier
Une fois dans Google Fusion table
- Cliquez sur create et sélectionner le fichier que vous venez de télécharger,
- Laissez comma comme séparateur
- Cliquez sur next, next, finish :)
Par défaut, GFT cherche un champ contenant de l’information géographique. Dans le cas de notre fichier, il va généralement prendre la colonne de l’arrondissement comme information géographique. Ce n’est pas totalement faux, mais ça manque de précision alors que nous avons à notre disposition des coordonnées exactes.
- Cliquez sur le titre de la colonne
nom_arrond, cliquez sur change, et dans le champ type, choisir text (au lieu de location). - Cliquez sur le titre de la colonne
latet vérifier qu’il est de type location et Two column location et que les bons champs sont sélectionés (respectivementlatetlng).
Maintenant, Google Fusion Tables va être capable de lire de l’information très précise. Cliquez sur l’onglet map of lat… voilà!
Malheureusement ce n’est pas très esthétique. Si vous cliquez sur un arbre, vous pouvez obtenir un info-window avec des informations spécifiques, mais là encore la mise en forme laisse à désirer.
Amélioration de l’info window
Ce point est facile à améliorer: cliquez sur le titre de l’onglet map of lat et cliquer sur Change info window layout. Par défaut, vous pouvez ajouter/retirer certains champs. Vous pouvez aussi cliquer sur custom et mettre un extrait HTML. Par exemple celui-ci:
<div style="height:200px" class='googft-info-window'>
<h4>{essence_francais}
<br>{rue}</h4>
<b>Diamètre:</b> {dhp} cm<br>
<b>Date de plantation:</b> {date_plant}
</div>
Sauvegardez les modifications et retournez voir les info-window dans le carte: c’est (un peu) mieux. (Ça pourrait encore être amélioré…)
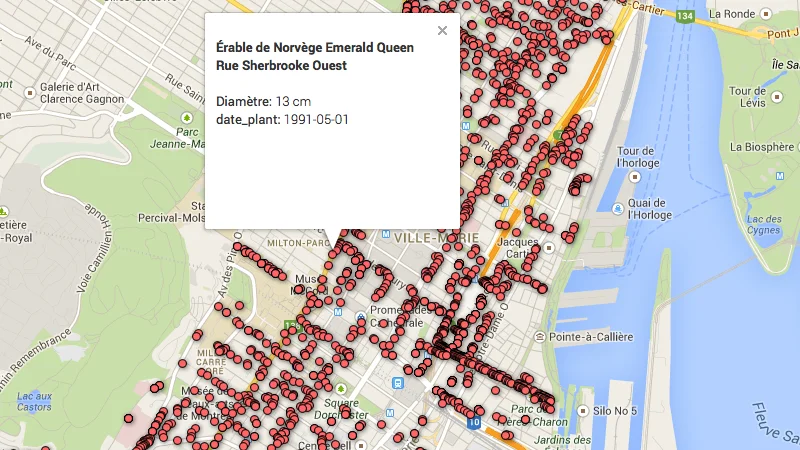
Il serait également possible de modifier les icones en fonction de l’essence de l’arbre, mais c’est franchement pénible. Il faudrait créer une nouvelle colonne dans le tableau contenant le nom de l’icône à utiliser.
Forces et faiblesses de Google Fusion Table
Pour:
- Facile d’utilisation
- Bonne gamme d’outils
- Geocoding intégré (non utilisé dans notre cas) mais non exportable
Contre:
- Le rendu final laisse à désirer
- Customisation difficile. En l’occurrence, il n’y a pas manière directe et facile de mettre en évidence l’essence de l’arbre ou sa taille.
- Le browser doit faire tout le travail. Cela peut devenir difficile à gérer avec des dizaines de milliers de points
- Limité dans les fonctionnalités géospatiales (par exemple, il n’a pas été possible d’otenir des coordonnées utilisables, alors que cela est possible avec CartoDB.)
Visualisation avec CartoDB
CartoDB est également relativement simple mais offre sous le capot bien plus de fonctionnalités: comme le laisse entendre le nom, CartoDB fournit une véritable base de données géospatiale, PostGIS. Bien que cela ne soit pas toujours nécessaire, cela peut vous rendre service. Ce service est gratuit lorsque l’on reste en-deça de 5MB mais devient payant au-delà.
Allez sur le site de CartoDB et créez un compte gratuit.
Cette fois-ci, pas de triche: nous allons utiliser le fichier obtenu après manipulation dans Open Refine, fichier qui ne contient pas des coordonnées utilisables.
Gérer les données géospatiale
Avant de rentrer dans le détail, quelques explications sur les fameuses données géospatiales: nous vivons sur une planète imparfaitement sphérique. Sauf que pour toutes sortes de raisons, nous manipulons depuis toujours des données mises sur un plan. D’où la nécessité d’utiliser des projections, mécanisme par lequel on peut représenter (et mesurer!) la surface d’une sphère, même imparfaite, sur un plan.
Malheureusement, ce mécanisme certaines limitations (qui se comprennent quand si on essaie d’étendre une peau d’orage sur une table). Il créé des distortions de toutes sortes. Il existe donc toutes sortes de projections, chacune avec ses défauts. Bien souvent, les organismes publics gèrent leurs informations dans une projections locale (optimisée pour la région voulue et donc minimisant les défauts) tandis que la majorité des outils (GFT, CartoDB, etc.) fonctionnent plutôt avec des projections globales reposant sur des coordonnées de format latitude/longitude.
C’est notre cas ici: le fichier de la ville utilise une projection locale répondant au doux nom de Québec MTM Zone 8 - Mercator Transverse modifié ayant l’identifiant 2950 et utilisant le mètre comme unité. Nous voulons transformer cette projection en WGS84, le système de coordonnées du système GPS et qui utilise le degré comme unité.
Un peu de magie
L’élément important des paragraphes qui suivent n’est pas nécessairement que vous sachiez le faire. L’important réside dans la relative simplicité de la chose. Si jamais vous faites face à ce genre de situation, une fois l’information dans CartoDB, une personne ayant quelques connaissances en géomatique pourrait vous aider en quelques minutes.
Par ailleurs, les Internets regorgent d’informations pertinentes. Personnellement, j’ai tout trouvé/appris sur Internet.
Première étape: Créer une colonne contenant les informations géospatiales
SELECT addgeometrycolumn ('NOM_DE_LA_TABLE', 'the_geom', 4326, 'POINT', 2)
Remplacez NOM_DE_LA_TABLE par le nom que CartoDB a donné à votre table. the_geom est le nom de la nouvelle colonne, tandis que 4326, POINT et 2 représentent respectivement la projection utilisée pour la colonne, le type d’information (des points) et le nombre de dimensions (nous n’avons pas l’information d’élévation… et c’est tant mieux.)
Étape deux: Remplir la colonne
update NOM_DE_LA_TABLE
set the_geom =
ST_Transform(
ST_PointFromText(
'POINT(' || "x" || ' ' || "y" ||')'
, 2950)
, 4326)
C’est un peu plus complexe mais expliqué simplement ça donne: On crée un point (ST_PointFromText) à partir des colonnes x et y, et on mentionne à la base de données que les coordonnées doivent être interprété dans la projection MTM8. Une fois le point créé, on le transforme (ST_transform) en point dans le référentiel 4326 qui, incidemment, est celui spécifié lors de la création de la colonne. Et on assigne le résultat à la colonne the_geom avec la commande UPDATE.
La carte et son amélioration
Maintenant nous avons des données géospatiales comprises par CartoDB, donc nous avons une carte: cliquez sur map view. Encore une fois, le résultat est imparfait: des tonnes de points indiscernables les uns des autres.
Pour cet aspect, CartoDB fournit des outils un peu plus efficaces que GFT.
En mode map, cliquez sur le bouton CSS (onglet latéral droit) et collez ceci dans la zone texte (en remplaçant NOM_DE_LA_TABLE par le nom que CartoDB a assigné à votre table):
#NOM_DE_LA_TABLE{
marker-fill: #333;
marker-opacity: 0.6;
marker-allow-overlap: true;
marker-placement: point;
marker-type: ellipse;
marker-line-width: 1;
marker-line-color: #FFF;
marker-line-opacity: 0.9;
[ dhp >= 0]{marker-width: 3;}
[ dhp >= 20]{marker-width: 5;}
[ dhp >= 50]{marker-width: 7;}
[ dhp >= 50]{marker-width: 9;}
}
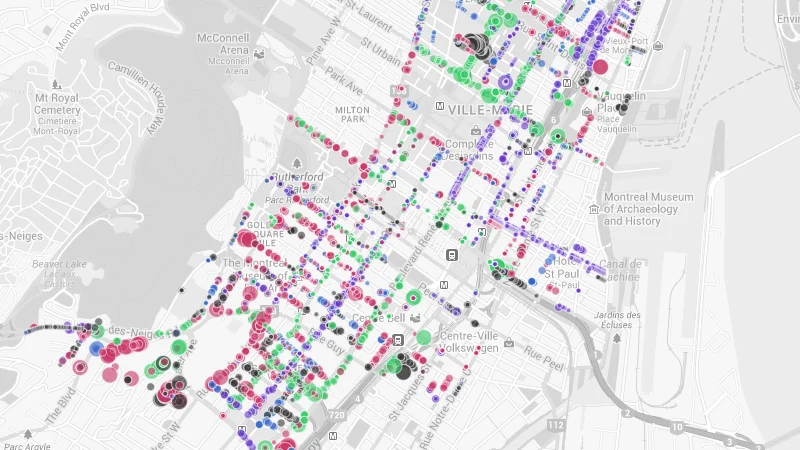
Maintenant, la carte est plus intéressantes. Qu’a-t-on fait? CartoDB est compatible avec une fonctionnalité développée par MapBox qui permet de modifier les marqueurs en fonction de déclaration et de sélecteurs (à la façon de CSS si vous êtes familiers avec l’univers du design web).
Toutes les lignes commençant par marker-... désignent les valeurs par défaut des marqueurs (couleur, transparence, ligne de contours, etc.). Les lignes commençant par des crochets sont des conditions sur un champ de la table. En l’occurrence dhp est la colonne contenant le diamètre de l’arbre. Une ligne comme [ dhp >= 50]{marker-width: 7;} spécifie donc que si le diamètre est supérieur à 50 (centimètres), le taille du marqueur doit être de 7.
Modifier la couleur du marqueur en fonction de l’essence de l’arbre
Idéalement, on souhaite regrouper les arbres par famille (frênes, érables, etc.). Malheureusement, les données fournies contiennent les essences spécifiques: érable ceci, érable cela, érable truc. Trop difficile à représenter. Nous souhaiterions, pour fins pédagogiques, regrouper les arbres par famille, déterminer les 4 principales familles et leur attribuer une couleur spécifique.
Nous allons donc créer une colonne pour stocker uniquement la famille:
alter table NOM_DE_LA_TABLE
add column racine_essence text
Et ensuite nous remplissons cette colonne avec la valeur adéquate:
update NOM_DE_LA_TABLE
set racine_essence = split_part(essence_francais, ' ', 1)
Note: L’étape précédente aurait aussi pu être réalisée via Excel… split_part scinde aux espaces le contenu de la colonne de l’essence en français et conserve juste le premier mot, qui par chance correspond à la famille.
Nous allons déterminer quelles sont les familles les mieux représentées:
select racine_essence, count(racine_essence) as comptage
from NOM_DE_LA_TABLE
group by racine_essence
order by comptage DESC
On obtient ainsi les quatre principales familles: érable, févier, frêne et orme.
Donc nous allons assigner des couleurs spécifiques aux quatre essences les plus représentées. Les autres conserveront la couleur par défaut.
#NOM_DE_LA_TABLE {
marker-fill: #333;
marker-opacity: 0.6;
marker-allow-overlap: true;
marker-placement: point;
marker-type: ellipse;
marker-line-width: 1;
marker-line-color: #FFF;
marker-line-opacity: 0.9;
[ dhp >= 0]{marker-width: 3;}
[ dhp >= 20]{marker-width: 5;}
[ dhp >= 50]{marker-width: 7;}
[ dhp >= 50]{marker-width: 9;}
[ racine_essence = "Érable"]{marker-fill: #cc3366;}
[ racine_essence = "Févier"]{marker-fill: #6633cc;}
[ racine_essence = "Frêne"]{marker-fill: #3366cc;}
[ racine_essence = "Orme"]{marker-fill: #33cc66;}
}
Voilà!
Forces et faiblesses de CartoDB
Pour
- Amélioration du design facile
- Meilleur véhicule d’information
- Engin (presque) complet pour gérer les données géospatiales
Contre
- Plus complexe!! Mais reste assez accessible simple…
- Payant à partir d’une certaine taille d’information…
Considérations générales
Un jeu de données complémentaire à l’inventaire des arbres est celui de la canopée. La canopée se définit par la surface couverte par les arbres. Tandis que l’inventaire permettra de chercher de l’information sur les arbres spécifiquement (et par exemple localiser tous les frênes et donc les zones à risque pour l’agrile du frêne), la canopée permettra de faire des études concernant les îlots de chaleur par exemple. Mais avec la canopée, on perd toute la métadonnée à propos des arbres individuels.
Par ailleurs manipuler des points est relativement simple. Des outils comme Google Fusion Table font l’affaire car l’information se représente sous forme de deux champs simples (latitude, longitude). Pour les structures plus complexes comme les surfaces (représentées par des polygones complexes), tout devient nettement plus difficile.
Enfin, afficher une information n’est souvent qu’une première étape. Souvent il sera nécessaire de croiser cette information avec d’autres informations pour obtenir quelque chose qui a du sens. Pour toutes sortes de raison, il est visuellement difficile de juger en détail quels microquartiers sont bien couverts en arbres.
Idéalement, il faut donc utiliser créer un système de découpage (soit un quadrillage ad hoc, soit un découpage existant comme ceux de Statistique Canada) et ensuite calculer le nombre d’arbres par zone ou la superficie couverte par zone. Ceci est nettement plus difficile à réaliser. L’article Considérations de visualisation de données montre justement un exemple où on passe des dons individuels (où certes, des zones peuvent être distinguées mais pas partout) au vainqueur en don par district électoral.
Encore une fois: plus difficile ne veut pas dire inaccessible. Internet regorge d’information sur le sujet et encore une fois j’ai pu réaliser ce genre de tâche en me basant principalement sur Internet.