Vivons-nous un moment iPhone ou Netscape avec ChatGPT? En 1994 ou 2006, ces deux technologies ne représentaient pas un bon technique extraordinaire, toutefois elles ouvraient un nouveau monde à notre imaginaire collectif et à notre quotidien. Il y a beaucoup à dire sur le potentiel, les limites et les dérives potentielles de ChatGPT et ses dérivés, toutefois dans ce billet je partage comment j’ai exploré de manière concrète le fonctionnement et la capacité d’apprentissage de cette technologie.
Comme je le dis souvent, il n’est pas nécessaire d’être mécano pour comprendre l’impact des voitures sur nos villes et nos vies. Toutefois, au moment où une technologie est encore naissante, comprendre et suivre la progression du fonctionnement et des capacités peut s’avérer nécessaire pour évaluer ses conséquences potentielles. La voiture avait un impact différent dans sa forme archaïque: un véhicule peu fiable, relativement lent et à l’autonomie limitée, il en est tout autrement aujourd’hui (je vous fais grâce de mes diatribes sur la nécessité d’infrastructures autour).
Par ailleurs, la déferlante ChatGPT m’a questionné sur deux points en particulier que je voulais creuser:
- Quel pouvait être l’usage de cette technologie sur un de mes projets en cours?
- Comment une technologie comme GPT est déjà utilisée par entreprises en “intelligence artificielle”?

Bref, pas de traité de machine learning ici -j’en serais bien incapable, mais plus une mise en exemple de l’utilisation concrète d’un outil.
Est-ce nécessaire de le signaler, ce billet est un produit 100% pur humain, rien n’a été produit par un modèle génératif, sauf ce qui est explicitement décrit comme tel! J’ai toutefois soumis le contenu de ce billet à ChatGPT pour lui demandé d’évaluer la véracité ou d’éventuelles imprécisions. Son intervention m’a permis de corriger ou préciser 3 éléments erronés ou effectivement vraiment imprécis.
Une brève histoire de code de sécurité routière
Un des projets que j’accompagne actuellement se penche sur l’innovation réglementaire. Un des problèmes de la réglementation est sa faible accessibilité au commun des mortels. Or, ChatGPT se distingue notamment par sa capacité à faire une synthèse souvent assez juste de contenus complexes. ChatGPT n’a pas été entrainé sur tous les règlements de la Terre: quelques questions rapides sur des règlements que je connais m’ont rapidement convaincu de ses limites là-dessus. Et ChatGPT ne peut pas être réentrainé.
En revanche, son modèle sous-jacent, GPT-3, offre quelques options pour lui apprendre quelques tours. Est-ce que ce sera suffisant? Je vous le dis tout de suite: non ou en tous cas pas comme je l’ai fait. Mais comme souvent, ce n’est pas uniquement la destination qui compte, le chemin a aussi son intérêt.
J’aurais pu me lancer dans la réglementation d’urbanisme, toutefois je me disais qu’il serait plus facile de procéder avec une forme de règlement que je connais et qui est plus court. Je me suis donc tourné vers le Code de sécurité routière, et plus précisément j’ai extrait les articles relatifs à la pratique du vélo, environ 70 articles. Ça sera notre terrain de jeu pour le reste de cet article.
Un peu de théorie
Avant de passer à la pratique, quelques éléments de théorie, même si cette information est largement disponible. ChatGPT et GPT-3 sont des LLM: Large Language Models. Un modèle de langage dans ce cas-ci veut dire un réseau de neurones qui s’est fait balancer une grande quantité de texte (le corpus d’entrainement). À partir de ce corpus, le modèle a “appris” que statistiquement telle lettre suivait telle autre lettre, que tel bloc de lettre suivait tel autre bloc de lettre, etc. Un modèle comme GPT ne “comprend” pas ce qu’il reçoit ou produit, il aligne des blocs de lettres (ou des tokens) qui sont logiques de manière statistique. Si vous êtes curieux, je vous invite à regarder cette petite vidéo où l’auteur apprend à un modèle assez simplifié, type GPT-2, comment faire du (mauvais) Shakespeare.
OpenAI a produit plusieurs modèles. Sous la grande gamme de GPT-3, ils ont plusieurs modèles de texte (Ada, Babbage, Curie et Davinci) et des modèles de programmation comme le fameux Codex. Malheureusement OpenAI n’est pas très loquace sur comment ont été produit ces différents modèles, mais on peut imaginer qu’ils ont des niveaux de complexité et de données d’entrainement différents. À titre d’exemple, Ada est plus rapide, moins coûteux et bon des tâches simples comme extraire des mots-clés d’un texte; ses données d’entrainement vont jusqu’en 2
- Demandez à Ada d’écrire un billet de blogue à votre place et vous risquez d’être déçu. DaVinci est les plus puissant, entrainé jusqu’en 2021, et il peut produire du contenu riche (moins bien que ChatGPT toutefois) ou faire des sommaires d’assez bonne qualité. D’après ChatGPT lui-même, son fonctionnement est basé sur Davinci, bonifié avec une approche de renforcement supervisé et de “reward”: des humains interviennent pour fournir des réponses souhaitables ou pour classer des réponses fournies par le modèle. Le modèle apprend ainsi le type de réponse qui est le plus désirable. Cet article est celui expliquant le mieux la démarche; OpenAI vient également de publier les règles qu’ils utilisent pour cette phase de renforcement.
Un petit pas de recul avant de continuer: malgré toutes les critiques et questions que, comme beaucoup de monde, j’ai à l’égard de cette technologie et d’OpenAI, il faut tout de même reconnaitre le tour de force que représente ChatGPT. On critique (à juste titre) les faiblesses de ChatGTP, ses erreurs, ses incohérences, mais c’est tout de même in-croy-able qu’un bidule dont le principe de fonctionnement est de calculer statistiquement la probabilité de blocs de caractères arrive à recevoir de l’information (une question) et de produire en contre-partie une information neuve -neuve au sens que personne ne l’a écrit, à défaut d’avoir de nouvelles idées
- à peu près indiscernable de ce que produirait un humain. La puissance de ce genre de modèle s’exprime aussi dans son application à l’art graphique où la même approche donne vie à DALL-E ou MidJourney qui produisent des images sur base d’indications textuelles. Tout ceci me semble simplement renversant. Ce qui ne veut pas dire que c’est une bonne chose, en fait c’est même un cas classique d’hubris où l’humain est subjugué par sa propre création. Fin du pas de recul.
–
Quoiqu’il en soit: pour utiliser ces modèles de manière pratique et pour leur apprendre des tours, il faut des outils et des API (des mécanismes qui permettent de dialoguer programmatiquement avec un système, ici un modèle de langage) qui ne sont pas (encore) disponibles pour ChatGPT, mais qui le sont pour les autres modèles de OpenAI. GPT-3 sera donc notre terrain de jeu.
OpenAI, offre deux options pour rendre GPT-3 plus informé sur un sujet:
- Le fine-tuning qui consiste à créer une nouvelle version d’un modèle en lui balançant autant de paires questions / réponses que possible, selon un format bien précis. Cela permet de lui donner une indication de comment répondre à certains types de questions. Ceci correspond à une des trois étapes de processus de renforcement supervisé utilisé pour ChatGPT. Techniquement, ce n’est pas un nouvel apprentissage, ça n’accroit pas directement le corpus d’entrainement, c’est plus un moyen de préciser la manière dont le modèle répond à certaines questions. Par la bande, il intègre quand même certaines informations.
- L’embedding qui est plus un tour de passe-passe qu’un réel apprentissage. L’embedding fournit des outils pour sélectionner des informations pertinentes sur le sujet qui nous intéresse, puis d’envoyer lesdites informations pertinentes à GPT-3 en même temps qu’on lui envoie la question. Ça peut sembler un peu archaïque, mais ça offre des résultats intéressants.
Commençons par les résultats
Pour ceux qui parcourent les articles à la recherche des résultats, c’est ici qu’il faut s’arrêter!
Métho rapide (quand même):
- j’ai préparé un jeu d’une quarantaine de questions relatives à la pratique du vélo que j’ai soumis à 4 modèles: ChatGPT, GPT-3 Davinci, GPT Davinci fine-tuné et GPT-3 Davinci avec une procédure d’embedding.
- Chaque réponse a été évaluée sur une échelle de 0 à 4. - 0: Réponse fausse et dangereuse - 1: Réponse fausse ou réponse à côté de la question - 2: Réponse avec un mélange de vrai et de faux - 3: Réponse globalement fausse avec des imprécisions ou erreurs secondaires - 4: Réponse complète avec citation des articles du code pertinents. Donc un modèle qui aurait une valeur de 4 dans les tableaux suivants aurait serait parfait pour toutes les questions. La capacité à citer l’article est importante pour retracer la source et pouvoir la valider; c’est par ailleurs une des grandes faiblesses de ChatGPT aujourd’hui: citer des sources fiables.
J’ai fait du prompt engineering, c’est-à-dire que j’ai fait plusieurs essais pour voir ce qui, de manière générale, fournissait les meilleurs résultats. Par exemple, chaque question se termine pas “Selon quel article de loi?” pour forcer le modèle à déclarer sa source… ce qui ne marche pas toujours.
J’ai fait 4 catégories de questions:
- Des questions simples, formulées selon un vocabulaire proche au code de sécurité routière;
- Des questions nécessitant des déductions ou des combinaisons d’information provenant de plusieurs articles;
- Des questions avec des formulations courantes notamment s’éloignant du vocabulaire présent dans le code et souvent sous la forme d’affirmation plutôt que de questions;
- Des propositions stupides, hors sujet, pour voir la réaction de chaque modèle. Voici un tableau synthèse des résultats:
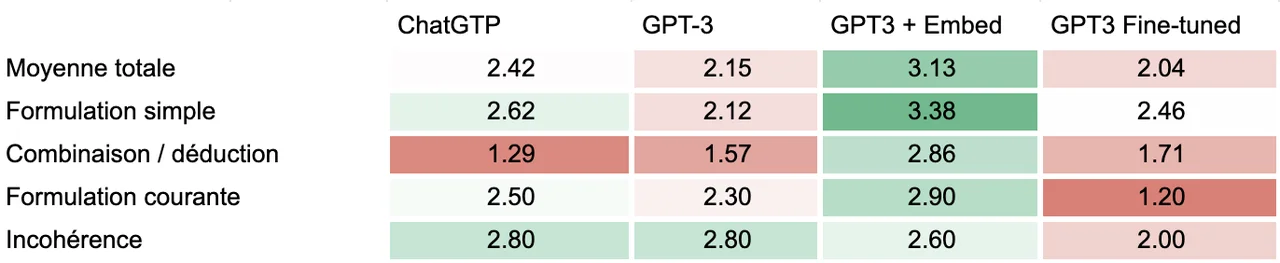
Comme nous pouvons le voir, nous avons un gagnant clair: l’embedding! Malheureusement c’est une approche qui est possiblement plus difficile à mettre en œuvre à grande échelle comme je vais l’expliquer plus tard (patience…) L’approche d’embedding donne des résultats systématiquement meilleurs que le GPT-3 de base et que ChatGPT, sauf pour les formulations incohérentes (le nombre de cas de formulation incohérente était assez bas donc difficile d’aller chercher une réelle signification statistique pour des petites différentes). Surtout la bonne note de l’embedding est liée à une faculté particulière de cette approche: bien citer les articles. Malgré cette bonne performance relative, avec une moyenne de 3.38/4 pour les questions simples, ça demeure insuffisant, à mes yeux, pour en faire une source fiable d’information…
Le perdant est le fine-tuning qui répond généralement moins bien que le GPT-3 de base sauf pour les formulations simples qui sont celles qui se rapprochent le plus des questions/réponses fournies dans la procédure fine-tuning. Attention cependant: la qualité du fine-tuning dépend de la quantité et de la qualité des exemples fournis. Ma quantité était un peu faible: 150, OpenAI recommande 200 comme minimum avec une augmentation significative de la qualité des réponses pour chaque doublement du nombre d’exemples. On comprend que c’est donc un processus assez demandant en temps humain…
Voici une autre petite illustration des résultats de manière plus détaillée avec la note de chaque modèle (les lignes) pour chaque question (les colonnes):
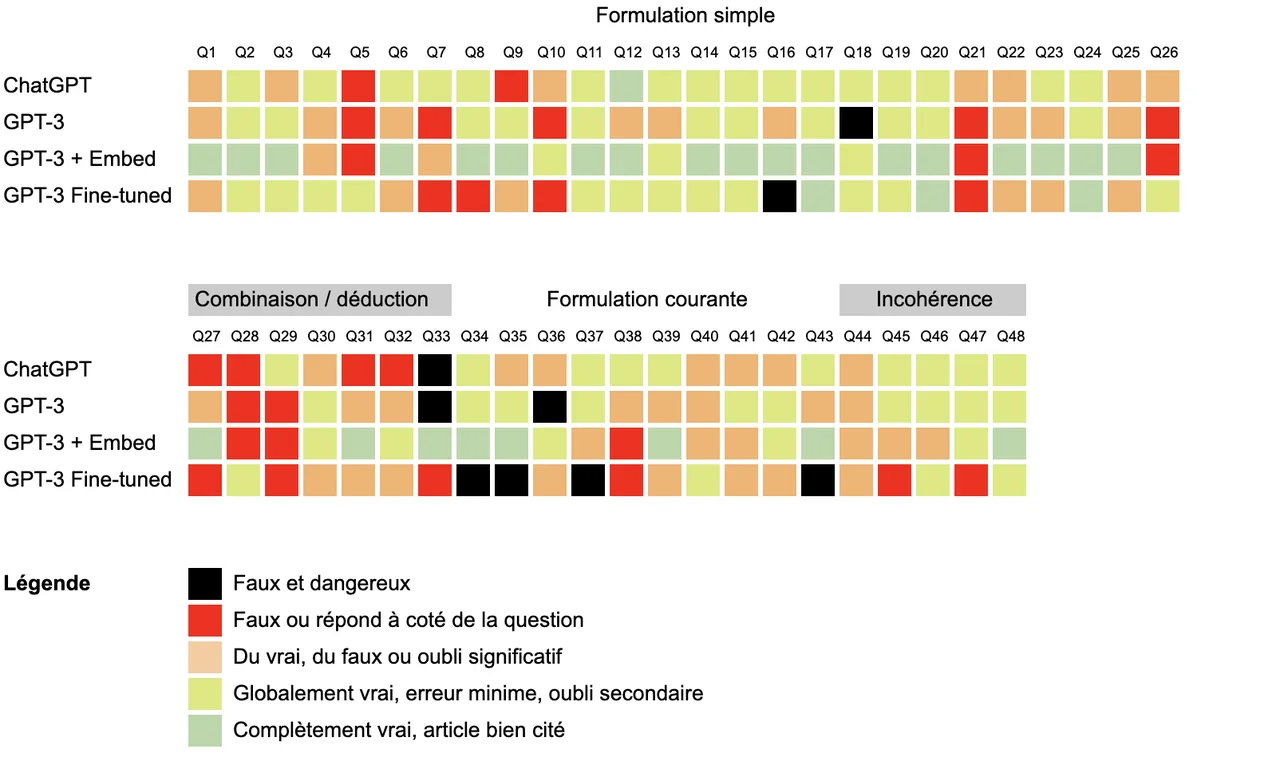
Quelques remarques:
- Comme on peut le voir, l’embedding est le seul à obtenir de manière régulière des notes parfaites alors que ChatGPT, tout en ayant beaucoup de “globalement vrai », n’a qu’un seul parfaitement exact, incluant le bon article (ça a tout l’air d’un coup de chance);
- ChatGPT s’en sort grâce à sa connaissance d’ensemble: la majorité des codes de sécurité routière suivent les mêmes grands principes et ChatGPT répond bien aux questions qui auraient une réponse sensiblement similaire ailleurs dans le monde. Là où il trébuche, ce sont souvent des cas plus spécifiques au Québec.
- On note que l’embedding permet de répondre correctement à certaines questions que tous les autres plantent. Par exemple pour les questions 22, 25 ou 2
- À noter aussi que l’embedding est le seul modèle à ne pas avoir de réponse noire: fausse et dangereuse.
- Le fine-tuning, pour sa part, est aussi capable de répondre par moment à des questions que tous les autres plantent (p.ex questions 5 ou 26), mais il est notoirement plus dangereux que les autres avec 5 réponses fausses et dangereuses, principalement sur les formulations de question s’éloignant beaucoup des exemples fournis.
Quelques exemples
Les éléments précédents sont un peu théoriques, donc voici quelques exemples concrets:
- Question 5:
Au Québec, à quelle distance minimale un véhicule routier doit-il suivre une bicyclette? Selon quel article de loi?- GPT-3:Selon l'article 486.1 du Code de la sécurité routière du Québec, un véhicule routier doit suivre une bicyclette à une distance minimale d'un mètre.- GPT-3 fine-tuned:Selon l'article 310 du Code de sécurité routière du Québec, un véhicule routier doit suivre une bicyclette à une distance prudente et raisonnable en tenant compte de la vitesse, de la densité de la circulation, des conditions atmosphériques et de l'état de la chaussée.Au-delà de l’invention d’un article qui n’existe pas, la réponse de GPT-3 est carrément dangereuse! Comme ChatGPT et la version avec embedding, GPT-3 confond la distance pour suivre et la distance latérale de dépassement. Seule la version fine-tuned a correctement interprété la question et sa réponse est parfaite… sauf le numéro de l’article qui est incorrect. Incidemment, une question assez similaire, mais tout de même différente figurait dans le jeu de données fourni pour le fine-tuning.
Autre exemple, cette-fois-ci d’une question nécessitant une combinaison:
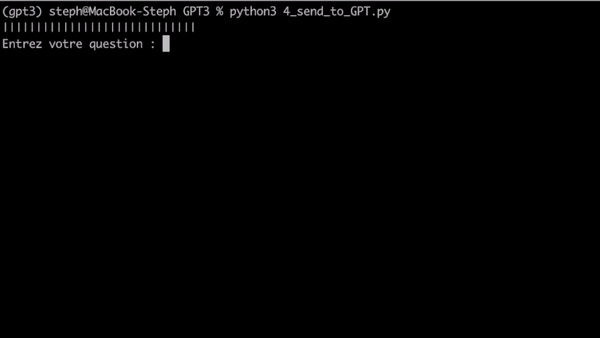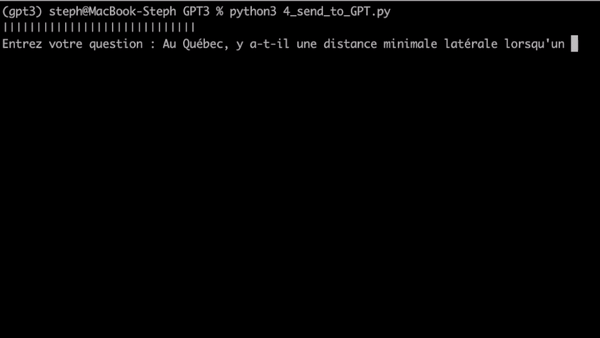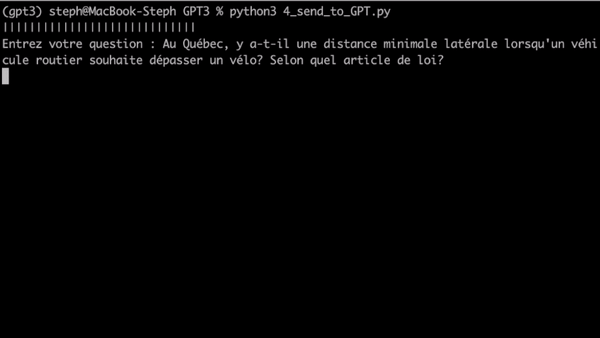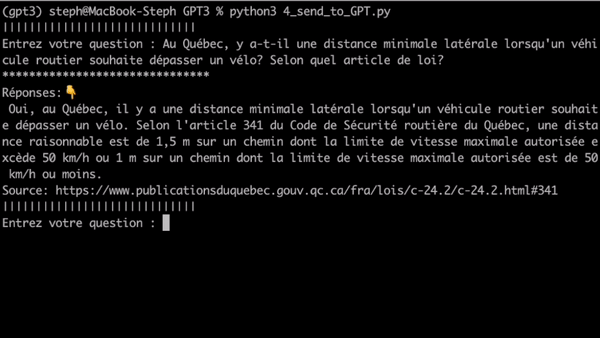
- Question 27:
Au Québec, quel est le montant de l'amende pour un conducteur de vélo n'ayant pas de système de frein? Selon quel article de loi?- ChatGPT:Au Québec, le montant de l'amende pour un conducteur de vélo n'ayant pas de système de frein est de 100 $ à 200 $. Cette infraction est prévue à l'article 251 du Code de la sécurité routière.- GPT-3 Embedding:Selon l'article 275.1 du Code de Sécurité routière du Québec, les propriétaires et les cyclistes dont les vélos ne sont pas conformes aux exigences des articles 212, 232, 233, du deuxième alinéa de l'article 235 ou des articles 237 ou 247 sont passibles d'une amende de 80 $ à 100 $.ChatGPT cite un article au hasard et se plante sur la valeur de l’amende. GPT-3 en mode embedding cite l’ensemble des articles correctement et obtient la bonne valeur d’amende, il est juste dommage qu’il ne souligne pas que c’est l’article 247 qui oblige le système de frein. À noter que c’était une surprise pour moi, car ça prend une forme de déduction: trouver l’article qui spécifie l’obligation d’un système de frein et ensuite l’article contenant la valeur de l’amende pour une infraction à cet article. Comme nous le verrons, cet aspect n’était pas gagné sachant la manière donc fonctionne l’embedding.
Dernier exemple, cette fois-ci avec une formulation plus courante où tous les modèles nous évitent d’avoir un comportement dangereux, sauf la version fine-tunée:
- Question 34:
Au Québec, c'est cool: quand je suis en vélo je peux trainer mon ami qui est en skate- GPT-3 Embedding:Non, il n'est pas permis de trainer un ami qui est en skate lorsque l'on est en vélo au Québec. Cette pratique est interdite selon l'article 434.0.1 du Code de Sécurité routière du Québec.Source: Code de Sécurité routière du Québec, article 434.0.1. - GPT-3 Fine-tuné:
Oui, c'est cool. En vertu de l'article 487 du Code de sécurité routière du Québec, un cycliste peut tracter un autre véhicule ou une personne sur un skateboard ou tout autre appareil motorisé sur une bicyclette dotée d'un moteur.
Réponse déjantée et dangereuse…
Vous pouvez accéder aux questions et aux réponses de chaque modèle ici.
Mais comment y marche le truc?
Si la technicité ne vous chaut pas plus que ça, vous pouvez sauter directement à la courte discussion qui fait office de conclusion. Ça ne va pas être outrageusement technique, et même pas du tout, mais des termes comme vecteur ou produit vectoriel pourraient apparaitre au détour d’un paragraphe.
L’embedding
Comme je l’ai laissé entendre, l’embedding, c’est un peu de la triche, mais de la triche élégante. Faute de pouvoir réentrainer GPT-3 sur de nouvelles données, il est possible de tirer profit de sa capacité d’analyse textuelle pour extraire l’information pertinente d’un contenu existant. Dans ce cas, GPT utilise assez rigoureusement l’information fournie. L’idéal serait de balancer TOUT le code de sécurité routière avec la question. Sauf que voilà: même le plus performant des modèles, Davinci, peut juste ingurgiter 4000 tokens (soit 3000 mots environ). Notre de code de sécurité routière est trop volumineux pour rentrer là-dedans, de beaucoup.
Alors que faire? Une solution proposée par OpenAI consiste à segmenter l’ensemble de l’information en bouts digestes, par exemple par article du Code, et ne fournir que les bouts pertinents pour répondre à la question. Le défi: Comment décider quels sont les bouts pertinents? Là encore, OpenAI nous donne un coup de main: Embedding API et quelques exemples.
Le principe: OpenAI utilise la capacité de compréhension de GPT-3 pour faire un rapprochement sémantique de mots ou groupes de mots. Les mots ou groupes de mots sont représentés par un point dans un espace à N dimension. Si deux points sont proches dans cet espace, ils concernent grosso modo la même chose. On est habitué à mettre des points sur des espaces à 2 ou 3 dimensions. GPT gère des espaces significativement plus compliqués: quand on lui soumet un mot ou un groupe de mots, l’API retourne un vecteur à plus de 1500 dimensions. La proximité s’obtient en calculant la similarité cosinus de deux vecteur, mais comme l’API OpenAI produit des vecteurs normalisés, un simple produit vectoriel permet d’obtenir la distance entre deux points.
Pour faire marcher tout cela, il faut procéder en deux étapes: la préparation et l’exécution.
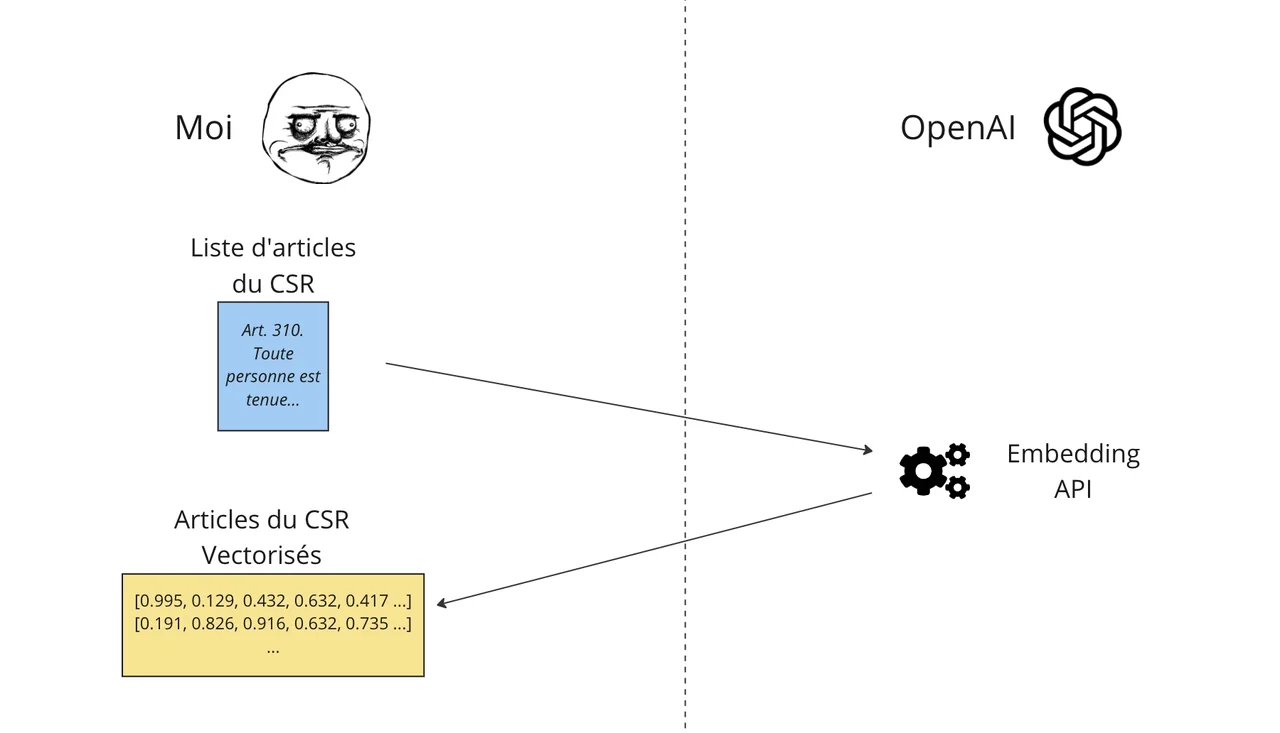
Pour la phase de préparation, on découpe le Code de sécurité routière par article et on envoie chaque article à l’API qui va nous retourner un vecteur que l’on peut stocker dans un fichier JSON combinant chaque article et son vecteur. Schématiquement, ça donne ceci:
Ensuite, quand on reçoit une question, on envoie également la question à l’API Embedding, qui nous renvoie un joli vecteur. Ensuite, on fait un produit vectoriel entre le vecteur question et tous les vecteurs articles et on classe le tout par proximité. Histoire d’être digeste, je sélectionne les articles les plus proches de sorte que la longueur des articles fournis en contexte ne dépasse pas 500 tokens. Et enfin on peut envoyer la question avec le contexte:
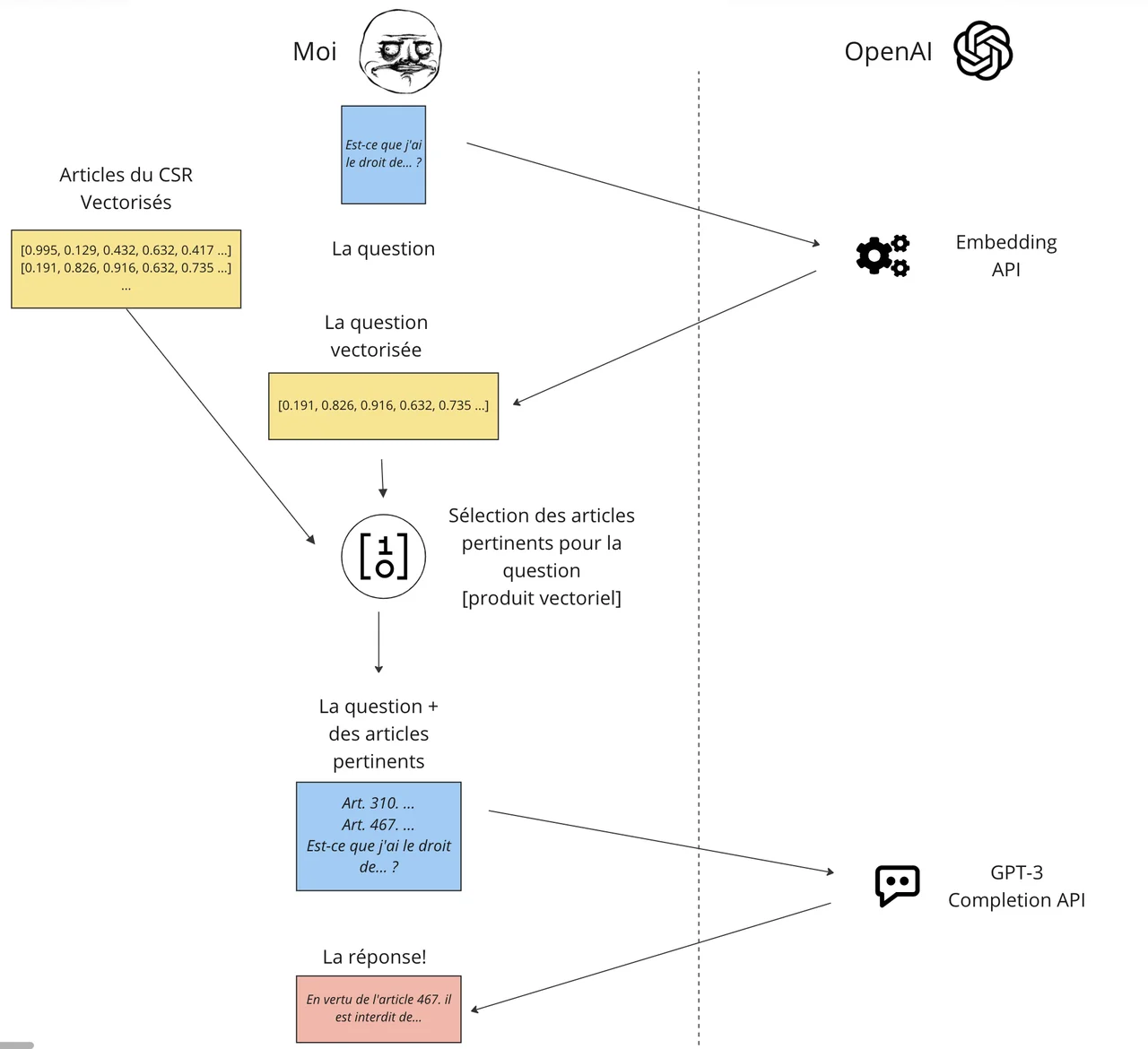
Bien franchement, je n’y croyais pas trop trop en me lançant dedans, mais la capacité de l’API Embedding à faire des rapprochements se traduit clairement par les bons chiffres de cette méthode comparativement aux autres. Possiblement qu’un texte de loi, facile à segmenter en article, est un cas d’utilisation particulièrement adapté, mais c’est tout de même significatif.
Je n’ai pas trouvé d’information claire sur le fonctionnement de Bing en mode ChatGPT (ou de BARD AI de Google), mais je suppose que pour être capable de répondre à des questions d’actualité (donc du contenu sur lequel le modèle n’a pas pu être entrainé), une approche similaire est utilisée.
Toute cette gymnastique ne peut évidemment pas se faire à la main. Chaque étape a été faite avec des petits scripts en Python, y compris la dernière étape qui interroge GPT-3 en lui envoyant le contexte. Comme je ne code pas souvent, j’ai demandé l’aide de ChatGPT pour faire mes scripts. Ce fut utile, mais pas délirant non plus.
Le fine-tuning
L’idée du fine-tuning est de fournir au modèle une série de prompt (des questions) et de completion (des réponses) pour le guider dans ses réponses. Comme on le comprend assez clairement au regard des résultats, le fine-tuning n’est pas un moyen pour apprendre de nouveaux faits à GPT-
- S’il était capable d’apprendre par cœur des nouveaux faits via le fine-tuning, les résultats auraient été significativement meilleurs pour cette approche.
Le fine-tuning sert plus à orienter le modèle dans la manière dont il construit ses réponses. Je n’ai pas lu d’explication détaillée sur le sujet, mais considérant comment fonctionne GPT, on peut considérer que ça influence la pondération des enchainements de caractères les plus probables en ajustant les poids des connexions neuronales du modèle. Évidemment, plus on fournit d’exemples, plus on est capable d’infléchir la génération de texte. Mais encore une fois GPT, ne va pas stocker dans une case mémoire une réponse à une question spécifique.
Là aussi, on procède en deux étapes. Étape 1, la préparation. Préparation un peu plus laborieuse que pour l’embedding puisqu’il faut produire des exemples de questions et réponses. Je visais 200, à savoir le chiffre recommandé par OpenAI. Comme je suis feignant, j’ai demandé à ChatGPT de faire le travail. Pour chacun des 70 articles traitant de vélo, je lui demandais 3 questions et réponses en spécifiant une structure de réponses assez répétitive: En vertu de l’article NNN, il est interdit de blablabla.
Ce fut quand même assez pénible et ChatGPT n’a pas toujours été un bon élève. Parfois il ne respectait pas le format, parfois il comprenait mal l’article du code (et il faut bien dire que certains articles sont rédigés de manière somme toute tarabiscotée). Il n’était pas rare que sur les 3 propositions, je n’en conserve que deux, voire une seule et que je doive en retravailler une partie.
L’ensemble des questions-réponses fut formaté comme prescrit par OpenAI. Là, encore la magie d’un appel d’API permettant de créer un nouveau modèle GPT en envoyant les 150 exemples construits et de recevoir l’identifiant unique du modèle créé. Si vous êtes curieux, ici aussi, il existe des recettes prêtes à l’emploi, ou presque.
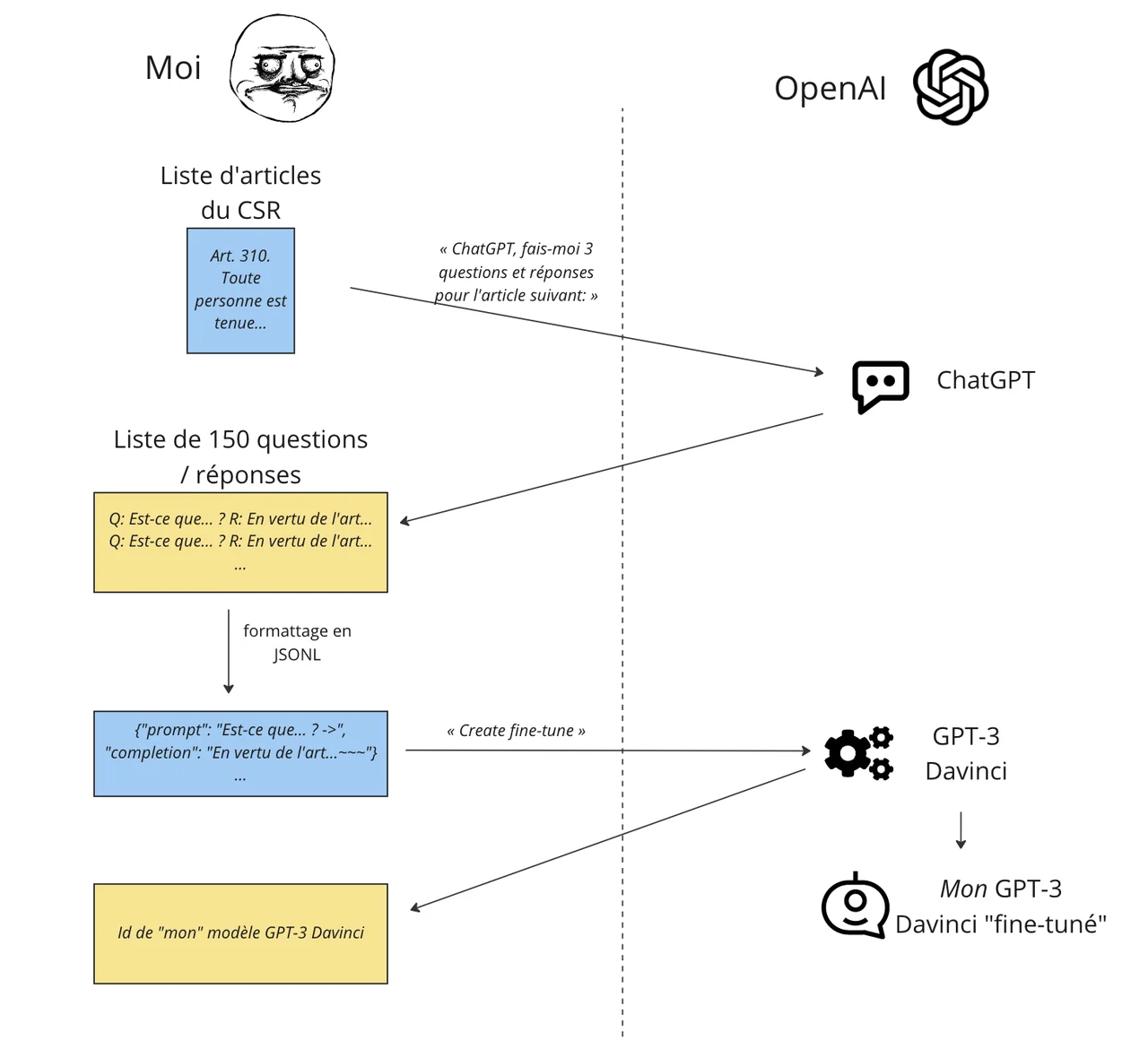
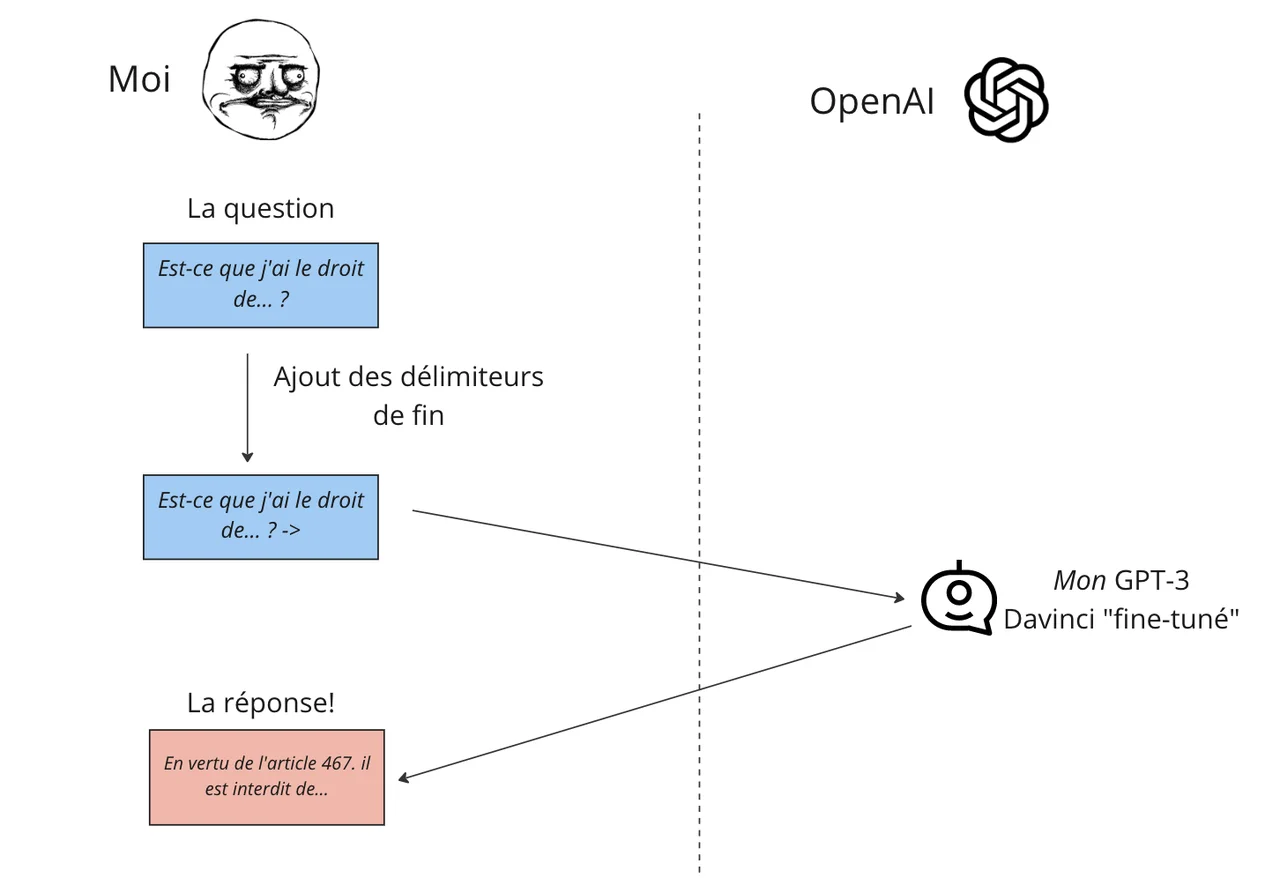
Afin de rendre le fine-tuning plus efficace, OpenAI recommande d’utiliser des séparateurs de fin autant pour la question que la réponse. Ces séparateurs doivent idéalement avoir très peu de chance de se retrouver dans les exemples fournis ou lors de l’exécution, dans mon cas j’ai utilisé -> pour le prompt et ~~~ pour la completion. Ces séparateurs doivent être fournis pour les exemples et lors de l’exécution. Pour la question, le séparateur permet vraisemblablement à GPT-3 de faire le lien entre les exemples et une question soumise.
Pour le séparateur de fin de completion, qui doit être fourni comme paramètre lors de l’exécution, il sert à indiquer à GPT-3 quand arrêter sa logorrhée. À certaines reprises, j’ai oublié de fournir le séparateur de fin lors de ma requête d’exécution. Dans ces cas-ci, GPT-3 se mettait à débagouler, fournissant du texte incohérent ou répétant sans fin certains caractères, dont le séparateur de fin.
Une fois qu’on a réalisé tout cela, il est possible d’interroger le modèle fine-tuné soit à travers un appel d’API, soit à travers le “Playground”, une interface graphique simple pour interagir avec GTP- 3.
Utiliser GPT-3 via Playground permet de comprendre d’autres choses; par exemple cette incapacité à citer correctement le numéro d’articles du Code. C’est déjà connu que les nombres ne sont pas la force de ChatGPT (et donc de GPT-3). Playground permet de faire apparaitre en code couleur la probabilité de chaque chaine de caractère tel que calculé par le modèle et même les alternatives envisagées. Voici un exemple ci-dessous:
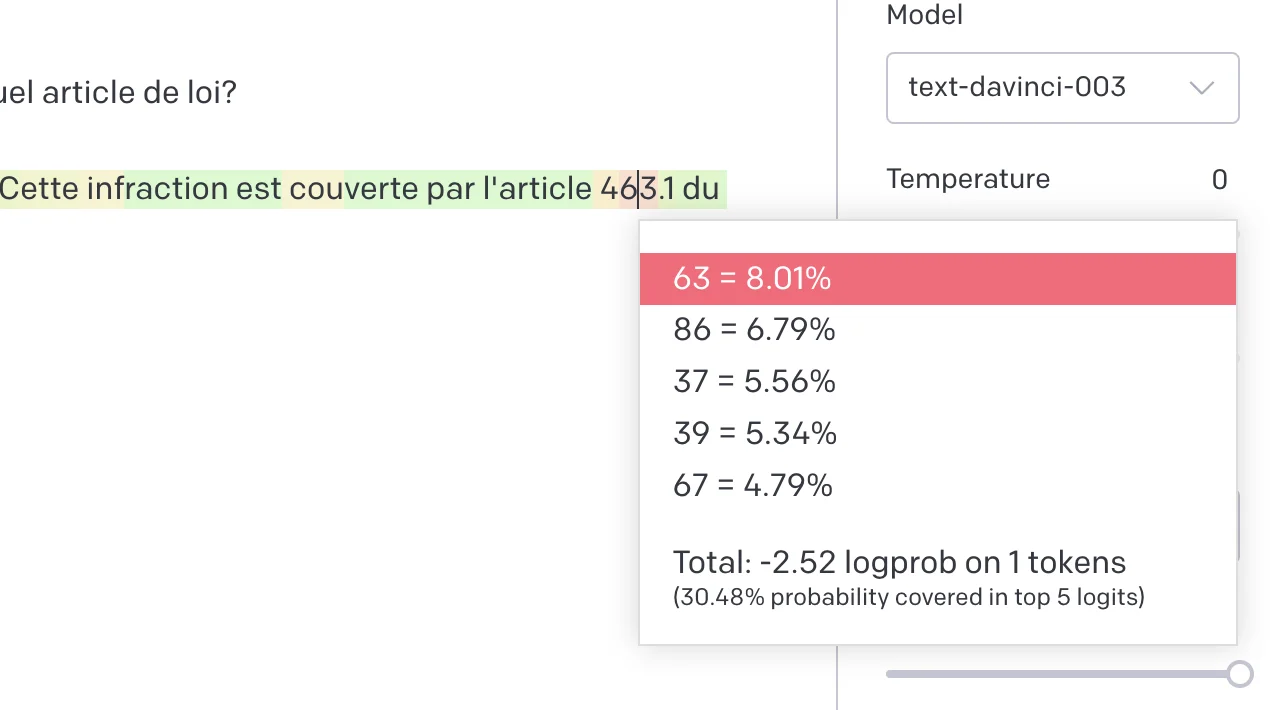
En vert, la probabilité de la chaine est élevée, plus on va vers le rouge et moins la probabilité de la chaine sélectionnée était élevée. Non seulement les nombres sont plus dans le rouge, mais plus on “avance” dans un nombre, moins le résultat est probable. Dans le cas ci-dessus, GPT-3 aurait aussi bien pu invoquer l’article 463, 486, ou encore 4 39.
Bien qu’un modèle comme GPT ne comprenne pas au sens cognitif ce qu’il écrit, l’approche est basée la notion d’attention qui est capable dans une certaine mesure d’avoir une notion de cohérence. Or, un numéro d’article de loi n’a pas de cohérence sémantique, c’est du par cœur. Et là-dessus GPT n’est pas fort fort.
Bizarrement, on retrouve un phénomène similaire chez Midjourney qui peut être considéré comme la version visuelle de GPT. La kryptonite de MidJourney? Les lettres et les doigts, et plus précisément le nombre de doigts. 6, 9, 12 doigts… qu’est-ce que ça change?

Pour finir sur cette expérience: GPT-3 n’est pas gratuit. Lorsqu’on crée un compte, on a droit à un certain nombre de tokens gratuits en lecture et écriture, correspondant à 18$. L’ensemble de mes expérimentations à couter l’équivalent de 7,52$. Ce n’est pas beaucoup, mais il faut bien se rendre compte que si on souhaite faire un chatbot ou une solution quelconque nécessitant pas mal de contexte (e.g d’embedding) ou pour laquelle on est capable de fournir beaucoup d’exemples de fine-tuning, le coût peut monter assez rapidement.
Conclusion pas finale
J’ai l’intention de faire un billet spécifiquement sur l’impact de cette technologie. Je veux ici souligner quelques éléments qui ressortent de cette tentative d’apprendre le code de sécurité routière à GPT- 3.
Pas mal de monde le savait déjà et avait écrit sur le sujet, je l’ai confirmé par curiosité intellectuelle: GPT-3 ne peut pas apprendre de nouvelles choses au-delà de son entrainement. Plus important, considérant son mode de fonctionnement, le mieux que l’on peut faire est soit de lui fournir un contexte très précis, soit essayer d’influencer ses réponses en lui fournissant des exemples. Dans un cas comme dans l’autre, on atteint une limite.
Si je reviens à l’idée de l’utiliser pour comprendre la réglementation en urbanisme de Montréal, je ne suis pas très confiant en l’état actuel des choses. Ce n’est pas non plus une raison pour mettre de côté cette technologie. L’approche d’embedding, bien loin d’être parfaite, offre tout de même des résultats intéressants dans un contexte où GPT-3 est qualitativement loin de ChatGPT. Un ChatGPT doté des mêmes fonctions que GPT-3 (API d’embedding notamment) pourrait être assez impressionnant, et ce n’est pas nécessairement loin dans le future. Par ailleurs, il faut bien avoir conscience que la technologie est encore jeune et que mon expérimentation s’est faite en quelques heures de temps personnel. On est loin d’une démarche professionnelle…
D’autant que ChatGPT a un autre as dans sa manche: il est capable de soutenir une conversation assez longue et il possède une mémoire de dialogue comme il me l’a lui-même expliqué. Qu’est-ce que cela change? Lorsqu’on fait de l’embedding avec GPT-3, on atteint rapidement la limite de contexte qu’il est possible de lui fournir. Or la mémoire de dialogue de ChatGPT permettrait, en théorie, de lui envoyer tout le code de sécurité routière comme conversation et puis de le questionner à volonté et à tout moment sur ce contenu. Là encore ChatGPT m’a confirmé que cela serait théoriquement possible (dois-je le croire?)
Il y aurait encore beaucoup à dire sur ce que j’ai appris en jouant ainsi avec GPT-3, toutefois ce texte est déjà assez long. Ce n’est là qu’un début, cette technologie va continuer d’évoluer de manière surprenante. Un prochain billet sera consacré à l’analyse de ChatGPT selon la lentille des principes d’innovation.